i
「i」とは・「i」の意味
英語のアルファベット「i」は、様々な単語や表現で使用される。一般的には、代名詞の「I」(私)や、数学用語の虚数単位「i」などがよく知られている。また、「i」は、接頭辞としても機能し、単語に特定の意味を付加することがある。例えば、「in-」や「im-」は否定の意味を持ち、「inter-」は「間」や「相互」の意味を表す。「i」の発音・読み方
英語の「i」の発音は、短母音と長母音の2種類が存在する。短母音の場合、IPA表記では/ɪ/となり、カタカナでは「イ」と表記される。例えば、""bit""(ビット)のような単語で使われる。長母音の場合、IPA表記では/aɪ/となり、カタカナでは「アイ」と表記される。例えば、""bite""(バイト)のような単語で使われる。「i」の定義を英語で解説
英語で「i」の意味を解説する場合、以下のような定義が考えられる。 1. The ninth letter of the English alphabet. 2. A pronoun used to refer to oneself as the speaker or writer. 3. A symbol used in mathematics to represent the imaginary unit. 4. A prefix used in various words to convey specific meanings, such as negation or interaction.「i」の類語
「i」に類似した意味を持つ単語や表現は、以下のようなものがある。 1. myself(自分自身) 2. imaginary unit(虚数単位) 3. in-(接頭辞、否定の意味) 4. inter-(接頭辞、間や相互の意味)「i」に関連する用語・表現
「i」に関連する用語や表現は、以下のようなものがある。 1. iPhone(アイフォン、Apple社のスマートフォン) 2. iMac(アイマック、Apple社のデスクトップコンピュータ) 3. iambic(イアンビック、詩の韻律の一種) 4. ibuprofen(イブプロフェン、鎮痛・解熱薬の一種)「i」の例文
1. I am a student.(私は学生である。) 2. The imaginary number i is defined as the square root of -1.(虚数iは-1の平方根として定義される。) 3. The word ""invisible"" has the prefix ""in-"" which means ""not"".(「invisible」という単語には、「not」という意味の接頭辞「in-」がある。) 4. International relations involve interactions between countries.(国際関係は国家間の相互作用を含む。) 5. She bought a new iPhone.(彼女は新しいiPhoneを買った。) 6. He works on an iMac.(彼はiMacで仕事をする。) 7. The poem is written in iambic pentameter.(その詩はイアンビック・ペンタメーターで書かれている。) 8. She took ibuprofen to relieve her headache.(彼女は頭痛を和らげるためにイブプロフェンを服用した。) 9. I like to travel.(私は旅行が好きである。) 10. The prefix ""inter-"" in ""interact"" means ""between"" or ""mutual"".(「interact」の接頭辞「inter-」は、「間」や「相互」という意味である。)アイ【I/i】
i (アイ)

主要諸元
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
●仕様変更は、発表なく実施することがあります。なお、本仕様は、国土交通省届出数値です。 ※1:メーカーオプションのハイグレードサウンドシステム(6ポジション、8スピーカー)を装着した場合、車両重量は+10kgとなります。 ※2:燃料消費率は定められた試験条件での値です。お客様の使用環境(気象、渋滞等)や運転方法(急発進、エアコン使用等)に応じて燃料消費率は異なります。 ※3:前後タイヤサイズが異なりますので、前後間のタイヤローテーションはできません。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
※都合により製品の仕様を予告なく変更する場合があります。
(注:この情報は2008年3月現在のものです)
よう素原子
ヨージド
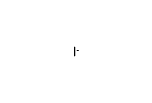
ヨード

ヨードニウム

イソロイシン
イノシン
I
I → イノシン (核酸)
I → イソロイシン (アミノ酸), Ile
- イソロイシン


I
I
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/10/10 15:47 UTC 版)

|
Ii Ii
|
|||||||||||||||||||||||||||||||
| ラテン文字 | |||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|||||||||||||||||||||||||||||||
Iは、ラテン文字(アルファベット)の9番目の文字である。小文字は i であるが、トルコ語とアゼルバイジャン語では点のない ı である。
字形


大文字は、一本の縦棒である。しかし、それではLの小文字や数字の 1 など混同し易い(ホモグリフ)せいもあって、手書き文字(ブロック体)であってもセリフを上下に付けて区別することがある。
同様にして、数字の 1 は飾りを上だけにする、数字の 7 は鉤を付ける、小文字の L は筆記体で ℓ と書く、というように区別することがある。
また、iだけを小文字にして、他の字を大文字にするのも見受けられる。
筆記体では、本体は下部が左に流れるが、ベースラインを超えない。また、右下から左に弧を描いて文字の頂点までの飾りを付ける。フラクトゥールは

 信号旗 手旗信号 点字
信号旗 手旗信号 点字
脚注
- ^ “Un solo nombre para cada letra” (スペイン語). Real Academia Española. 2022年12月31日閲覧。
関連項目
- Ì ì - グレイヴ・アクセント
- Í í - アキュート・アクセント
- Î î - サーカムフレックス
- Ï ï - トレマ
- Ī ī - マクロン
- Į į - オゴネク
- İ i - ドット符号
- IJ ij - 合字
| A | B | C | Ç | D | E | F | G | Ğ | H | I | İ | J | K | L | M | N | O | Ö | P | R | S | Ş | T | U | Ü | V | Y | Z |
| a | b | c | ç | d | e | f | g | ğ | h | ı | i | j | k | l | m | n | o | ö | p | r | s | ş | t | u | ü | v | y | z |
| A | B | C | Ç | D | E | Ə | F | G | Ğ | H | X | I | İ | J | K | Q | L | M | N | O | Ö | P | R | S | Ş | T | U | Ü | V | Y | Z |
| a | b | c | ç | d | e | ə | f | g | ğ | h | x | ı | i | j | k | q | l | m | n | o | ö | p | r | s | ş | t | u | ü | v | y | z |
ローマ数字
((ⅰ) から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/09/04 01:34 UTC 版)


|
この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。 (2016年12月)
|
ローマ数字(ローマすうじ)は、数を表す記号の一種である。ラテン文字の一部を用い、例えばアラビア数字における 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 をそれぞれ I, II, III, IV, V, VI, VII, VIII, IX, X のように表記する。I, V, X, L, C, D, Mはそれぞれ 1, 5, 10, 50, 100, 500, 1000 を表す。i, v, x などと小文字で書くこともある。現代の一般的な表記法では、1以上4000未満の数を表すことができる。
ローマ数字のことをギリシャ数字と呼ぶ例が見られるが、これは誤りである。
表記法
古代ローマにおいて成立し、中世後期までヨーロッパで一般的に用いられていた表記法。ただしこれを規定する公式な、あるいは広く知られた標準となる表記法は存在していない[注 1]。 16世紀頃からはアラビア数字での表記が一般的になったが、特定の場面においては現代でも用いられている。
十進法に基づいている。 数を10の冪ごとに、つまり 1000の位の量 + 100の位の量 + 10の位の量 + 1の位の量 と分解し、左からこの順番に書き下す。この際、空位の0は書かれることはない。位ごとに異なる記号が用いられるが、記号の組み合わせのパターンは共通である。
| ローマ数字 | I | V | X | L | C | D | M |
|---|---|---|---|---|---|---|---|
| アラビア数字 | 1 | 5 | 10 | 50 | 100 | 500 | 1000 |
それぞれの位の量は更に上記の数字の和に分解され、大きい順に並べて書かれる。5未満は Iの繰り返しで表され、5以上は Vに Iをいくつか加える形で表される。(画線法)
また、小さい数を大きい数の左に書くこともあり、この場合右から左を減ずることを意味する。これを減算則という。
| ローマ数字 | IV | IX | XL | XC | CD | CM |
|---|---|---|---|---|---|---|
| アラビア数字 | 4 | 9 | 40 | 90 | 400 | 900 |
これらの数は減算則を使わず表現することも可能(例:4 を「 IIII」、9を「 VIIII」)だが、通常は減算則を用いて表記する。なお、減算則が用いられるのは4 (40, 400) と9 (90, 900) を短く表記する場合だけであり、それ以外で使うことは通常行われない(例外は#異表記を参照のこと)。つまり、8を「 IIX」と表記したり、位ごとの分離を破って45を「 VL」、999を「 IM」と表記することは基本的でない書き方とされる。
以上を踏まえると、1 から 9 とその 10 倍と 100 倍、および1000、2000、3000は以下のような表記となる。
| ×1 | ×10 | ×100 | ×1000 | |
|---|---|---|---|---|
| 1 | I | X | C | M |
| 2 | II | XX | CC | MM |
| 3 | III | XXX | CCC | MMM |
| 4 | IV | XL | CD | [注 2] |
| 5 | V | L | D | |
| 6 | VI | LX | DC | |
| 7 | VII | LXX | DCC | |
| 8 | VIII | LXXX | DCCC | |
| 9 | IX | XC | CM |
これらを組み合わせることで、1 から 3999 の値が表現できる。だが言い換えれば、(パターンを守ろうとすると)4000以上の数値を表すことは不可能である。また、0 を表す記号は存在しない。このため、 0 の値が入る桁の数値は表記せず、そのまま空位とする。
また、整数と小数が一貫しておらず、整数が十進法(二五進法)である一方、小数には十二進法が適用され、1/12や1/144の小数が作られている。
小数は、3/12 (= 1/4)が「点3つ」、6/12 (= 1/2)が「S」、9/12 (= 3/4)が「Sに点3つ」として、六で一旦繰り上がる方法で表記されている。
ローマ数字の並べ方の例
| 12 | = | 10 × 1 | + | 1 × 2 | |||||||
| = | X | + | II | ||||||||
| = | XII | ||||||||||
|
|
|||||||||||
| 24 | = | 10 × 2 | + | (−1 + 5) | |||||||
| = | XX | + | IV | ||||||||
| = | XXIV | ||||||||||
|
|
|||||||||||
| 42 | = | (−10 + 50) | + | 1 × 2 | |||||||
| = | XL | + | II | ||||||||
| = | XLII | ||||||||||
|
|
|||||||||||
| 49 | = | (−10 + 50) | + | (−1 + 10) | |||||||
| = | XL | + | IX | ||||||||
| = | XLIX | ||||||||||
|
|
|||||||||||
| 89 | = | 50 | + | 10 × 3 | + | (−1 + 10) | |||||
| = | L | + | XXX | + | IX | ||||||
| = | LXXXIX | ||||||||||
|
|
|||||||||||
| 299 | = | 100 × 2 | + | (−10 + 100) | + | (−1 + 10) | |||||
| = | CC | + | XC | + | IX | ||||||
| = | CCXCIX | ||||||||||
|
|
|||||||||||
| 302 | = | 100 × 3 | + | (10 × 0) | + | 1 × 2 | |||||
| = | CCC | + | + | II | |||||||
| = | CCCII | ||||||||||
|
|
|||||||||||
| 493 | = | (−100 + 500) | + | (−10 + 100) | + | 1 × 3 | |||||
| = | CD | + | XC | + | III | ||||||
| = | CDXCIII | ||||||||||
|
|
|||||||||||
| 1960 | = | 1000 × 1 | + | (−100 + 1000) | + | 50 | + | 10 | + | (1 × 0) | |
| = | M | + | CM | + | L | + | X | ||||
| = | MCMLX | ||||||||||
|
|
|||||||||||
| 3999 | = | 1000 × 3 | + | (−100 + 1000) | + | (−10 + 100) | + | (−1 + 10) | |||
| = | MMM | + | CM | + | XC | + | IX | ||||
| = | MMMCMXCIX | ||||||||||
|
|
|||||||||||
なお、手書きでは、大文字のローマ数字は上下のセリフをつなげて書くことが多い。「V」は上部のセリフをつなぎ、逆三角形(▽)のようになる。小文字ではセリフを書かない。
時計の文字盤での表記
時計の文字盤は伝統的に4時を「 IIII」と表記することが多い。その由来には下記のように様々な説が唱えられているが定説はない。なお、9時は通常表記の「 IX」の場合が多い。また、4時を通常表記の「 IV」と表記している時計も存在しており、この表記方法は絶対的な物ではない(同様に、9時を「 VIIII」と表記している時計も存在する)。
- ローマ神話の最高神・ユピテル (IVPITER) の最初の2文字と重なるのを避けるため。
- 4を「 IV」と書くと「 VI」と見分けにくいため。
- 「 IIII」ならば「 I」という刻印を4回押せば文字盤の文字が作れるが、「 IV」だと専用の型が必要になる。
- 専用の文字を使うのは、ちょうど間が4時間おきになる V と X だけのほうがいい。
- 「 IIII」にすれば左側の「 VIII」と文字数が釣り合い、見栄えがよい。
- 特定の有力なローマの時計製造者が「 IIII」と書いた時計を作ったため、他の製造者もそれに倣った。
- ルイ14世が、文字盤に「 IV」を用いることを禁じた。
- シャルル5世が、「 IV」を用いることを禁じた。
異表記

- 減算の文字を複数並べる。(例)8 = IIX,80 = XXC
- 500 に「 D」を使わない。(例)1611 = MCCCCCCXI
- 減算を行わない。(例)1495 = MCCCCLXXXXV
- 任意の自然数 n に対し、10n を表す文字の前に、5m10n − 2 (m = 0, 1) 以下を表す文字を使う。(例)490 = -10 + 500 = XD
- 簡略表記。Microsoft Excel の ROMAN 関数で「書式4」を使用。(例)999 = IM
ローマ数字はもともと厳密な規則が定義されたものではなく、特に減算則に関しては様々な異表記が見られる。当初は減算則が存在しなかったため、4 を「 IIII」、9 を「 VIIII」と書いていた。「The Forme of Cury」(14世紀の著名な英語の料理解説書)は 4 = IIII、9 = IXと表記している一方で「 IV」と表記した箇所もある。
ほかに、80 = R、2000 = Zとする異表記もある。また、 1⁄2 = S、 1⁄12 = • などとする分数の記号もあった。
4000以上の大きな数字
前述の通り、4000以上の数値の表記は、パターンに従った通常の方法では不可能であり、1 から 3999 の数値までしか表記できない。現代ではあまり使用されないが、4000以上の表記は下記の方法によって行う。
- 重ね表記
1000 を表すのに「M」ではなく「ↀ」または「CIↃ」を用いる場合もある。5000 を「ↁ」または「IↃↃ」、10000 を「ↂ」または「CCIↃↃ」で表した例もある。同様にして 50000 は「ↇ」または「IↃↃↃ」、100000 は「ↈ」または「CCCIↃↃↃ」となる。
| 基本数字 | C| Ɔ (M) = 1,000 | CC| ƆƆ = 10,000 | CCC| ƆƆƆ = 100,000 |
| + | Ɔ (D) = 500 | C| Ɔ| Ɔ (MD) = 1,500 | CC| ƆƆ| Ɔ = 10,500 | CCC| ƆƆƆ| Ɔ = 100,500 |
| + | ƆƆ = 5,000 | - | CC| ƆƆ| ƆƆ = 15,000 | CCC| ƆƆƆ| ƆƆ = 105,000 |
| + | ƆƆƆ = 50,000 | - | - | CCC| ƆƆƆ| ƆƆƆ = 150,000 |
- つなぎ表記
-
通常のローマ数字に上線を付加することで、1,000 倍を表現する。また二重上線では 1,000,000 倍となる。すなわちn重の上線は 1,000n (1,000のn乗)倍を表す。
- 4,000 = IV = MV
- 5,300 = VCCC
- 6,723 = VIDCCXXIII = VMDCCXXIII
- 9,999 = IXCMXCIX = MXCMXCIX
- 51,200 = LICC
- 99,999 = XCIXCMXCIX
- 500,000 = D I
- 921,600 = C I XXIDC
- 3,000,000 = III
- 9,125,334 = IX CCXXVCCCXXXIV
- 91,200,937 = XCI CCCMXXXVII
- 235,002,011 = CCXXXV IIXI
-
前後に縦線を付加することで、さらに 100 倍(都合 100,000 倍)を表す。
- 800,000 = | VIII|
- 1,040,000 = | X| XL (= 10 × 1,000 × 100 + (-10 + 50) × 1,000) = I XL (= 1 × 1,000,000 + (-10 + 50) × 1,000)
用途

現在、ローマ数字は序数、章番号、ページ番号、文章の脚注番号などに使うことが多いが、酸化銅(II)など一部例外がある[2]。
- 英語圏では、ローマ教皇や国王の名前に使用される。
- イギリスでは、大学の学年表記の他、英国放送協会(BBC)が番組の製作年を表すのにローマ数字を使っており、エンドクレジットの最後で下部分に「MMXIII (2013)」などと表示される。
- 1980年代ごろまでは映画の著作権表示の制作年にローマ数字が使われることが多かった。例えば、1983年に発売されたタイトーの業務用ゲーム『エレベーターアクション』の著作権表記は「© TAITO CORP. MCMLXXXIII」となっている。
- 音楽理論では、音階の中での音の位置を表すのにローマ数字を用いる。最もよく用いられるのは和音の調の中での位置を表す時である。大文字と小文字は場合によって様々な意味で使い分けられる。手書きでは「i」の点を打たないのが普通である(それはしかも逆感嘆符である「¡」と見分けにくいという欠点もある)。
- 日本の公営競技の確定板でも、着順の表示に用いられている。
- 競馬の「GIレース」など、グレードを示す際にも利用される(グレード制)。
- 高等学校数学の科目名や大学入試類型など、教育部門で使用されている面が見られる。
- 『ドラゴンクエストII 悪霊の神々』や『ファイナルファンタジーIII』など、コンピュータゲームの続編ではローマ数字を使用したものがある。
- 陸上自衛隊の第14旅団、第15旅団などは部隊章にローマ数字を使用している。
ローマ数字の歴史
|
この節は検証可能な参考文献や出典が全く示されていないか、不十分です。 (2016年12月)
|
古代ローマ人は元々農耕民族だった。羊の数を数えるのに木の棒に刻み目を入れた。柵から1匹ずつヤギが出て行くたびに刻み目を1つずつ増やしていった。3匹目のヤギが出て行くと「III」と表し、4匹目のヤギが出て行くと3本の刻み目の横にもう1本刻み目を増やして「IIII」とした。5匹目のヤギが出て行くと、4本目の刻み目の右にこのときだけ「V」と刻んだ(∧と刻んだ羊飼いもいた)。このときの棒についた刻み目は「IIIIV」となる。6匹目のヤギが出て行くと、刻み目の模様は「IIIIVI」、7匹目が出て行くと「IIIIVII」となる。9匹目の次のヤギが出て行くと「IIIIVIIII」の右に「X」という印を刻んだ。棒の模様は「IIIIVIIIIX」となる。31匹のヤギは「IIIIVIIIIXIIIIVIIIIXIIIIVIIIIXI」と表す。このように刻んだのは、夕方にヤギが1匹ずつ戻ってきたときに記号の1つ1つがヤギ1匹ずつに対応していたほうが便利だったためである。ヤギが戻ると、記号を指で端から1個1個たどっていった。最後のヤギが戻るときに指先が最後の記号にふれていれば、ヤギは全部無事に戻ったことになる。50匹目のヤギはN、+または⊥で表した。100匹目は*で表した。これらの記号はローマのそばのエトルリア人も使った。エトルリアのほうが文明が栄えていたので、そちらからローマに伝わった可能性もある。1000は○の中に十を入れた記号で表した。
よく言われる「X」は「V」を2つ重ねて書いたもの、あるいは「V」は「X」の上半分という説は、誤りとは言い切れないが確たる根拠もないようである。
やがて時代が下り、羊以外のものも数えるようになると、31は単に「XXXI」と書くようになった。5はしばらく「V」と「∧」が混在して使われた。50は当初N、И、K、Ψ、などと書き、しばらく「⊥」かそれに似た模様を使ったが、アルファベットが伝わると混同して「L」となった。100は*だけでなくЖ、Hなどと書いたが、*がしだいに離れて「>|<」や「⊃|⊂」になり、よく使う数なので簡略になり、「C」や「⊃」と書きそのまま残った(ラテン語の"centum=100"が起源という説もある)。500は最初、1000を表す「⊂|⊃」から左の⊂を外し、「|⊃」と書いた。やがて2つの記号がくっつき、「D」となった。「D」の真ん中に横棒がついて「D」や「Ð」とも書いた。1000は○に十の記号が省略されて「⊂|⊃」となった。「∞」と書いた例もある。これが全部くっついたのが「Φ」に似た記号である。これが別の変形をし上だけがくっついて「m」に似た形になり、アルファベットが伝わると自然と「M」と書かれるようにもなった(ラテン語の"mille=1000"からも考慮されている)。そのため、1000は今でも2つの表記法が混在している。
5000以上の数は100と1000の字体の差から自然に決まった。ただし、「凶」を上下逆に書いた形(X)で1000000 (100万)を表したこともある。
古代ローマ共和国時代の算盤では、記号の上に横棒を引いて1000倍を表したものもある。この方法では、10000は「X」の上に横棒を1本引いたもので表される。100000 (10万) や1000000 (100万) は「C」や「M」の上に横棒を1本を引いて表した。たとえば10000は「X」となる。
例:CCX[注 3] = 210000 (21万)
数字の上部分に「 ̄」・左右に「|」をそれぞれつけて10万倍を表すこともあった(上と左右の線をくっつけて表記することも多い)。たとえば10(X)を10万倍した数=1000000 (100万) は、「X」と表記する。
例:
その後、他の文明との接触により変わった表記法が現れた。1世紀、プリニウスは著書『博物誌』で83000を「LXXXIII.M[注 6]」と表記した。83.1000 (83の1000倍) という書き方である。同じ文書中に、XCII.M [注 7](92000)、VM [注 8](5000) という表記もある。この乗算則はしばらく使われたようである。1299年に作成された『王フィリップ4世の財宝帳簿』では、5316を「VmIIIcXVI[注 9]」と表した。漢数字の書き方によく似ている。ただしこれらの乗算則は現在は使われない。
1000を超える数の表記法に混乱があるのは一般人は巨大な数を扱う機会がなかったためと考えられる。
その他
- Microsoft Excel のROMANという関数は 0 から 3999 までの数をローマ数字に変換する。範囲外の数ではエラー値「#VALUE!」が表示される。なお、0の場合はエラー値でなく空文字列を返す。
- 英語で100 ドル札を「C-bill」や「C-note」と呼ぶのはローマ数字の C に由来する[要出典]。
文字コードにおけるローマ数字
基本的には通常のラテン文字を並べてローマ数字を表現する。Unicode 以前から欧米で一般的に使用されている ISO/IEC 8859 などの文字コードは、ローマ数字専用の符号を持っていない。
JIS規格
日本で用いられる文字コードとしても、JIS X 0208 にはローマ数字専用の符号は定義されていない。これを拡張した Microsoftコードページ932 (CP932) や MacJapanese などにおいて、いわゆる機種依存文字として定義されており、追って JIS X 0213 にも取り入れられた。CP932 にあるのは大文字 I から X と小文字 i から x の合成済み 20 字 (1 から 10 に相当)、MacJapanese にあるのは 大文字 I から XV と小文字 i から xv の合成済み 30 字 (1 から 15 に相当)、JIS X 0213 は大文字 I から XII と小文字 i から xii の合成済み 24 字 (1 から 12 に相当) である。これらは縦書きの組版の際に縦中横を容易に実現するために用いられ(一般の組版ルールでローマ数字は縦中横である)、多くのフォントで全角文字としてデザインされる。
Unicode
Unicode は、JIS X 0213 などとの互換性のために上述の合成済みローマ数字を収録した上、その延長として Ⅼ, Ⅽ, Ⅾ, Ⅿ, ⅼ, ⅽ, ⅾ, ⅿ[注 10]、また通常のラテン文字にない Ↄ, ↄ, ↀ, ↁ, ↂ, ↇ, ↈ, ↅ, ↆ [注 11]も定義している。これらは U+2160 から U+2188 までの符号位置を割り当てられている。(Unicode 7.0.0 時点)〈登録領域〉Number Form(数字に準じるもの)
機械処理の注意点
ラテン文字と共通の符号を用いるため、「I」「V」「X」「L」「C」「D」「M」が機械処理の際にアルファベットそのものを表しているのか、数字の「1」「5」「10」「50」「100」「500」「1000」を表しているのか解釈を誤る場合がある。
符号位置
Unicodeに存在しないMacJapaneseのローマ数字 (XIII, XIV, XV, xiii, xiv, xv) は、Unicodeの私用領域にAppleが独自に定義した制御文字の後ろに組文字を構成する文字を続けることで表される[3]。
| 大文字 | Unicode | JIS X 0213 | 文字参照 | 小文字 | Unicode | JIS X 0213 | 文字参照 | 備考 |
|---|---|---|---|---|---|---|---|---|
| Ⅰ | U+2160 |
1-13-21 |
ⅠⅠ |
ⅰ | U+2170 |
1-12-21 |
ⅰⅰ |
ローマ数字1 |
| Ⅱ | U+2161 |
1-13-22 |
ⅡⅡ |
ⅱ | U+2171 |
1-12-22 |
ⅱⅱ |
ローマ数字2 |
| Ⅲ | U+2162 |
1-13-23 |
ⅢⅢ |
ⅲ | U+2172 |
1-12-23 |
ⅲⅲ |
ローマ数字3 |
| Ⅳ | U+2163 |
1-13-24 |
ⅣⅣ |
ⅳ | U+2173 |
1-12-24 |
ⅳⅳ |
ローマ数字4 |
| Ⅴ | U+2164 |
1-13-25 |
ⅤⅤ |
ⅴ | U+2174 |
1-12-25 |
ⅴⅴ |
ローマ数字5 |
| Ⅵ | U+2165 |
1-13-26 |
ⅥⅥ |
ⅵ | U+2175 |
1-12-26 |
ⅵⅵ |
ローマ数字6 |
| Ⅶ | U+2166 |
1-13-27 |
ⅦⅦ |
ⅶ | U+2176 |
1-12-27 |
ⅶⅶ |
ローマ数字7 |
| Ⅷ | U+2167 |
1-13-28 |
ⅧⅧ |
ⅷ | U+2177 |
1-12-28 |
ⅷⅷ |
ローマ数字8 |
| Ⅸ | U+2168 |
1-13-29 |
ⅨⅨ |
ⅸ | U+2178 |
1-12-29 |
ⅸⅸ |
ローマ数字9 |
| Ⅹ | U+2169 |
1-13-30 |
ⅩⅩ |
ⅹ | U+2179 |
1-12-30 |
ⅹⅹ |
ローマ数字10 |
| 大文字 | Unicode | JIS X 0213 | 文字参照 | 小文字 | Unicode | JIS X 0213 | 文字参照 | 備考 |
|---|---|---|---|---|---|---|---|---|
| Ⅺ | U+216A |
1-13-31 |
ⅪⅪ |
ⅺ | U+217A |
1-12-31 |
ⅺⅺ |
ローマ数字11 |
| Ⅻ | U+216B |
1-13-55 |
ⅫⅫ |
ⅻ | U+217B |
1-12-32 |
ⅻⅻ |
ローマ数字12 |
| 大文字 | Unicode | JIS X 0213 | 文字参照 | 小文字 | Unicode | JIS X 0213 | 文字参照 | 備考 |
|---|---|---|---|---|---|---|---|---|
| Ⅼ | U+216C |
‐ |
ⅬⅬ |
ⅼ | U+217C |
‐ |
ⅼⅼ |
ローマ数字50 |
| Ⅽ | U+216D |
‐ |
ⅭⅭ |
ⅽ | U+217D |
‐ |
ⅽⅽ |
ローマ数字100 |
| Ⅾ | U+216E |
‐ |
ⅮⅮ |
ⅾ | U+217E |
‐ |
ⅾⅾ |
ローマ数字500 |
| Ⅿ | U+216F |
‐ |
ⅯⅯ |
ⅿ | U+217F |
‐ |
ⅿⅿ |
ローマ数字1000 |
| Ↄ | U+2183 |
‐ |
ↃↃ |
ↄ | U+2184 |
‐ |
ↄↄ |
ローマ数字逆100 |
| 記号 | Unicode | JIS X 0213 | 文字参照 | 名称 |
|---|---|---|---|---|
| ↀ | U+2180 |
‐ |
ↀↀ |
ローマ数字1000 C D |
| ↁ | U+2181 |
‐ |
ↁↁ |
ローマ数字5000 |
| ↂ | U+2182 |
‐ |
ↂↂ |
ローマ数字10000 |
| ↇ | U+2187 |
‐ |
ↇↇ |
ローマ数字50000 |
| ↈ | U+2188 |
‐ |
ↈↈ |
ローマ数字100000 |
| ↅ | U+2185 |
‐ |
ↅↅ |
ローマ数字6 LATE FORM |
| ↆ | U+2186 |
‐ |
ↆↆ |
ローマ数字50 EARLY FORM |
| 記号の再現 | MacJapanese | 記号の再現 | MacJapanese | 名称 |
|---|---|---|---|---|
| XIII | 0x85AB | xiii | 0x85BF | ローマ数字13 |
| XIV | 0x85AC | xiv | 0x85C0 | ローマ数字14 |
| XV | 0x85AD | xv | 0x85C1 | ローマ数字15 |
脚注
注釈
- ^ 書き方ではなく読み方については以下の事例が参考になる――著作権法 (アメリカ合衆国)においてローマ数字による発行年表示が有効なものであるとされていて、不正なローマ数字は著作権表示を無効化しうる[1]。この際、下記のような書き方ルールに合致しているかどうかは問題とされない。
- ^ 詳しくは#4000以上の大きな数字を参照。
- ^ = [{(100 × 2) + 10} × 1000] = 210 × 1000 = 210000 (21万)
- ^ = [{1000 + 100 + 50 + (1 × 2)} × 100000] + [{(10 × 3) + 5 + (1 × 2)} × 1000] + {(100 × 2) + (10 × 3) + (1 × 2)} = 1152 × 100000 + 37 × 1000 + 232 = 115200000 (1億1520万) + 37000 + 232 = 115237232 (1億1523万7232)
- ^ = [{(1000 × 2) + (100 × 3) + (10 × 2) + (1 × 2)} × 100000] + (((50 + (10 × 2)) + 1) × 1000) + [(100 × 2) + (10 × 3) + {5 + (1 × 3)}] = 2322 × 100000 + 71 × 1000 + 238 = 232200000 (2億3220万) + 71000 + 238 = 232271238 (2億3227万1238)
- ^ = [{50 + (10 × 3)} × 1000] = 83 × 1000 = 83000
- ^ = [{(100 − 10) + 2} × 1000] = 92 × 1000 = 92000
- ^ = 5 × 1000 = 5000
- ^ = [(5 × 1000) + {(1 × 3) × 100} + (10 + 5 + 1)] = 5000 + 300 + 16 = 5316
- ^ 〔大文字〕U+216C, 216D, 216E, 216F〔小文字〕U+217C, 217D, 217E, 217F
- ^ (左から順に) U+2183, 2184, 2180, 2181, 2182, 2187, 2188, 2185, 2186
出典
- ^ Hayes, David P.. “Guide to Roman Numerals”. Copyright Registration and Renewal Information Chart and Web Site. 2021年11月29日閲覧。
- ^ 比留間直和 (2012年10月1日). “いつ使う?ローマ数字 - ことばマガジン”. 朝日新聞デジタル. 朝日新聞社. 2021年11月29日閲覧。
- ^ UnicodeコンソーシアムにあるMac OS Japaneseとの変換テーブル
関連項目
- 数字
- 画線法
- ↅ (ローマ数字) - 紀元初期から6世紀まで使われ、ↅⅠ(7)、ↅⅡ(8)、ↅⅢ(9)とも表記されていた。ギリシア数字のϚ(6)とも関連するとされる。
- クロノグラム - 碑文の中にローマ数字を入れて、年代を表記する方法
| 典拠管理データベース: 国立図書館 |
|---|
囲み英数字
((ⅰ) から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/07/08 07:52 UTC 版)
| 囲み英数字 | |
|---|---|
| Enclosed Alphanumerics | |
| 範囲 | U+2460..U+24FF (160 個の符号位置) |
| 面 | 基本多言語面 |
| 用字 | Common |
| 割当済 | 160 個の符号位置 |
| 未使用 | 0 個の保留 |
| Unicodeのバージョン履歴 | |
| 1.0.0 | 139 (+139) |
| 3.2 | 159 (+20) |
| 4.0 | 160 (+1) |
| 公式ページ | |
| コード表 ∣ ウェブページ | |
| 備考: [1][2] | |
囲み英数字(かこみえいすうじ、英語: Enclosed alphanumerics)は、Unicodeの84個目のブロックであり、丸や括弧で囲まれた英数字やピリオドつきの数字が収録されている。この他、Unicode バージョン 6.0で追加多言語面(SMP)に囲み英数字補助ブロックが追加された。
目的
囲み英数字の多くは元々箇条書き用に使用されていた[3]。括弧で囲まれた形式は、歴史的に、丸囲みの文字をタイプライターで表現しようとした形に基づいている[3]。これらの役割は、 リッチテキストにおいてはスタイルやマークアップに置き替えられた。しかし、東アジアの既存の文字コードとの互換性や、テキストファイルでそのような記号が使用される場合のために、囲み文字がUnicode標準に含まれている[3]。Unicode規格では、著作権や商標の記号として定義されている丸囲みのC・P・Rやアットマークなど、目的に特化した文字は囲み文字とは区別している[3]。
英数字を囲むすべての文字がこの区間にあるわけではないことに注意。 Unicode区間装飾記号(Dingbat)では、U+2777からU+2793まで、数字1から10を囲む黒文字、数字1から10を囲む非セリフ文字、数字1から10を囲む非セリフ黒文字の順にある。
収録文字
本ブロックに含まれる囲み文字は基本的に手順の順序や教育における小問などの番号付きリストを形成するために用いられる。
| コード | 文字 | 文字名(英語) | 用例・説明 |
|---|---|---|---|
| 丸囲み数字 | |||
| U+2460 | ① | CIRCLED DIGIT ONE | |
| U+2461 | ② | CIRCLED DIGIT TWO | |
| U+2462 | ③ | CIRCLED DIGIT THREE | |
| U+2463 | ④ | CIRCLED DIGIT FOUR | |
| U+2464 | ⑤ | CIRCLED DIGIT FIVE | |
| U+2465 | ⑥ | CIRCLED DIGIT SIX | |
| U+2466 | ⑦ | CIRCLED DIGIT SEVEN | |
| U+2467 | ⑧ | CIRCLED DIGIT EIGHT | |
| U+2468 | ⑨ | CIRCLED DIGIT NINE | |
| U+2469 | ⑩ | CIRCLED NUMBER TEN | |
| U+246A | ⑪ | CIRCLED NUMBER ELEVEN | |
| U+246B | ⑫ | CIRCLED NUMBER TWELVE | |
| U+246C | ⑬ | CIRCLED NUMBER THIRTEEN | |
| U+246D | ⑭ | CIRCLED NUMBER FOURTEEN | |
| U+246E | ⑮ | CIRCLED NUMBER FIFTEEN | |
| U+246F | ⑯ | CIRCLED NUMBER SIXTEEN | |
| U+2470 | ⑰ | CIRCLED NUMBER SEVENTEEN | |
| U+2471 | ⑱ | CIRCLED NUMBER EIGHTEEN | |
| U+2472 | ⑲ | CIRCLED NUMBER NINETEEN | |
| U+2473 | ⑳ | CIRCLED NUMBER TWENTY | |
| 括弧囲み数字 | |||
| U+2474 | ⑴ | PARENTHESIZED DIGIT ONE | |
| U+2475 | ⑵ | PARENTHESIZED DIGIT TWO | |
| U+2476 | ⑶ | PARENTHESIZED DIGIT THREE | |
| U+2477 | ⑷ | PARENTHESIZED DIGIT FOUR | |
| U+2478 | ⑸ | PARENTHESIZED DIGIT FIVE | |
| U+2479 | ⑹ | PARENTHESIZED DIGIT SIX | |
| U+247A | ⑺ | PARENTHESIZED DIGIT SEVEN | |
| U+247B | ⑻ | PARENTHESIZED DIGIT EIGHT | |
| U+247C | ⑼ | PARENTHESIZED DIGIT NINE | |
| U+247D | ⑽ | PARENTHESIZED NUMBER TEN | |
| U+247E | ⑾ | PARENTHESIZED NUMBER ELEVEN | |
| U+247F | ⑿ | PARENTHESIZED NUMBER TWELVE | |
| U+2480 | ⒀ | PARENTHESIZED NUMBER THIRTEEN | |
| U+2481 | ⒁ | PARENTHESIZED NUMBER FOURTEEN | |
| U+2482 | ⒂ | PARENTHESIZED NUMBER FIFTEEN | |
| U+2483 | ⒃ | PARENTHESIZED NUMBER SIXTEEN | |
| U+2484 | ⒄ | PARENTHESIZED NUMBER SEVENTEEN | |
| U+2485 | ⒅ | PARENTHESIZED NUMBER EIGHTEEN | |
| U+2486 | ⒆ | PARENTHESIZED NUMBER NINETEEN | |
| U+2487 | ⒇ | PARENTHESIZED NUMBER TWENTY | |
| ピリオド付き数字 | |||
| U+2488 | ⒈ | DIGIT ONE FULL STOP | |
| U+2489 | ⒉ | DIGIT TWO FULL STOP | |
| U+248A | ⒊ | DIGIT THREE FULL STOP | |
| U+248B | ⒋ | DIGIT FOUR FULL STOP | |
| U+248C | ⒌ | DIGIT FIVE FULL STOP | |
| U+248D | ⒍ | DIGIT SIX FULL STOP | |
| U+248E | ⒎ | DIGIT SEVEN FULL STOP | |
| U+248F | ⒏ | DIGIT EIGHT FULL STOP | |
| U+2490 | ⒐ | DIGIT NINE FULL STOP | |
| U+2491 | ⒑ | NUMBER TEN FULL STOP | |
| U+2492 | ⒒ | NUMBER ELEVEN FULL STOP | |
| U+2493 | ⒓ | NUMBER TWELVE FULL STOP | |
| U+2494 | ⒔ | NUMBER THIRTEEN FULL STOP | |
| U+2495 | ⒕ | NUMBER FOURTEEN FULL STOP | |
| U+2496 | ⒖ | NUMBER FIFTEEN FULL STOP | |
| U+2497 | ⒗ | NUMBER SIXTEEN FULL STOP | |
| U+2498 | ⒘ | NUMBER SEVENTEEN FULL STOP | |
| U+2499 | ⒙ | NUMBER EIGHTEEN FULL STOP | |
| U+249A | ⒚ | NUMBER NINETEEN FULL STOP | |
| U+249B | ⒛ | NUMBER TWENTY FULL STOP | |
| 括弧囲みラテン文字 | |||
| U+249C | ⒜ | PARENTHESIZED LATIN SMALL LETTER A | |
| U+249D | ⒝ | PARENTHESIZED LATIN SMALL LETTER B | |
| U+249E | ⒞ | PARENTHESIZED LATIN SMALL LETTER C | |
| U+249F | ⒟ | PARENTHESIZED LATIN SMALL LETTER D | |
| U+24A0 | ⒠ | PARENTHESIZED LATIN SMALL LETTER E | |
| U+24A1 | ⒡ | PARENTHESIZED LATIN SMALL LETTER F | |
| U+24A2 | ⒢ | PARENTHESIZED LATIN SMALL LETTER G | |
| U+24A3 | ⒣ | PARENTHESIZED LATIN SMALL LETTER H | |
| U+24A4 | ⒤ | PARENTHESIZED LATIN SMALL LETTER I | |
| U+24A5 | ⒥ | PARENTHESIZED LATIN SMALL LETTER J | |
| U+24A6 | ⒦ | PARENTHESIZED LATIN SMALL LETTER K | |
| U+24A7 | ⒧ | PARENTHESIZED LATIN SMALL LETTER L | |
| U+24A8 | ⒨ | PARENTHESIZED LATIN SMALL LETTER M | |
| U+24A9 | ⒩ | PARENTHESIZED LATIN SMALL LETTER N | |
| U+24AA | ⒪ | PARENTHESIZED LATIN SMALL LETTER O | |
| U+24AB | ⒫ | PARENTHESIZED LATIN SMALL LETTER P | |
| U+24AC | ⒬ | PARENTHESIZED LATIN SMALL LETTER Q | |
| U+24AD | ⒭ | PARENTHESIZED LATIN SMALL LETTER R | |
| U+24AE | ⒮ | PARENTHESIZED LATIN SMALL LETTER S | |
| U+24AF | ⒯ | PARENTHESIZED LATIN SMALL LETTER T | |
| U+24B0 | ⒰ | PARENTHESIZED LATIN SMALL LETTER U | |
| U+24B1 | ⒱ | PARENTHESIZED LATIN SMALL LETTER V | |
| U+24B2 | ⒲ | PARENTHESIZED LATIN SMALL LETTER W | |
| U+24B3 | ⒳ | PARENTHESIZED LATIN SMALL LETTER X | |
| U+24B4 | ⒴ | PARENTHESIZED LATIN SMALL LETTER Y | |
| U+24B5 | ⒵ | PARENTHESIZED LATIN SMALL LETTER Z | |
| 丸囲みラテン文字 | |||
| U+24B6 | Ⓐ | CIRCLED LATIN CAPITAL LETTER A | しばしば無神論(atheism)のシンボルとして用いられる。 |
| U+24B7 | Ⓑ | CIRCLED LATIN CAPITAL LETTER B | |
| U+24B8 | Ⓒ | CIRCLED LATIN CAPITAL LETTER C | 拡張IPAでは不明瞭な子音(consonant)を表す。 |
| U+24B9 | Ⓓ | CIRCLED LATIN CAPITAL LETTER D | |
| U+24BA | Ⓔ | CIRCLED LATIN CAPITAL LETTER E | |
| U+24BB | Ⓕ | CIRCLED LATIN CAPITAL LETTER F | 拡張IPAでは不明瞭な摩擦音(fricative)を表す。 |
| U+24BC | Ⓖ | CIRCLED LATIN CAPITAL LETTER G | 拡張IPAでは不明瞭な接近音(glide)を表す。 |
| U+24BD | Ⓗ | CIRCLED LATIN CAPITAL LETTER H | 地図記号ではしばしばホテルを表す。 ヘリポートのある場所にはこの記号が地面に表示されている。 |
| U+24BE | Ⓘ | CIRCLED LATIN CAPITAL LETTER I | |
| U+24BF | Ⓙ | CIRCLED LATIN CAPITAL LETTER J | |
| U+24C0 | Ⓚ | CIRCLED LATIN CAPITAL LETTER K | |
| U+24C1 | Ⓛ | CIRCLED LATIN CAPITAL LETTER L | 拡張IPAでは不明瞭な側面音(liquid/lateral)を表す。 |
| U+24C2 | Ⓜ | CIRCLED LATIN CAPITAL LETTER M | 地図記号ではしばしば地下鉄(metro)を表す。 絵文字が提供されている。 |
| U+24C3 | Ⓝ | CIRCLED LATIN CAPITAL LETTER N | 拡張IPAでは不明瞭な鼻音(nasal)を表す。 |
| U+24C4 | Ⓞ | CIRCLED LATIN CAPITAL LETTER O | |
| U+24C5 | Ⓟ | CIRCLED LATIN CAPITAL LETTER P | 拡張IPAでは不明瞭な破裂音(plosive)を表す。 |
| U+24C6 | Ⓠ | CIRCLED LATIN CAPITAL LETTER Q | |
| U+24C7 | Ⓡ | CIRCLED LATIN CAPITAL LETTER R | 拡張IPAでは不明瞭な流音(rhotic/resonant)を表す。 |
| U+24C8 | Ⓢ | CIRCLED LATIN CAPITAL LETTER S | 拡張IPAでは不明瞭な歯擦音(sibilant)を表す。 |
| U+24C9 | Ⓣ | CIRCLED LATIN CAPITAL LETTER T | 拡張IPAでは不明瞭な声調(tone)を表す。 |
| U+24CA | Ⓤ | CIRCLED LATIN CAPITAL LETTER U | |
| U+24CB | Ⓥ | CIRCLED LATIN CAPITAL LETTER V | 拡張IPAでは不明瞭な母音(vowel)を表す。 |
| U+24CC | Ⓦ | CIRCLED LATIN CAPITAL LETTER W | |
| U+24CD | Ⓧ | CIRCLED LATIN CAPITAL LETTER X | |
| U+24CE | Ⓨ | CIRCLED LATIN CAPITAL LETTER Y | |
| U+24CF | Ⓩ | CIRCLED LATIN CAPITAL LETTER Z | |
| U+24D0 | ⓐ | CIRCLED LATIN SMALL LETTER A | |
| U+24D1 | ⓑ | CIRCLED LATIN SMALL LETTER B | |
| U+24D2 | ⓒ | CIRCLED LATIN SMALL LETTER C | |
| U+24D3 | ⓓ | CIRCLED LATIN SMALL LETTER D | |
| U+24D4 | ⓔ | CIRCLED LATIN SMALL LETTER E | |
| U+24D5 | ⓕ | CIRCLED LATIN SMALL LETTER F | |
| U+24D6 | ⓖ | CIRCLED LATIN SMALL LETTER G | |
| U+24D7 | ⓗ | CIRCLED LATIN SMALL LETTER H | |
| U+24D8 | ⓘ | CIRCLED LATIN SMALL LETTER I | |
| U+24D9 | ⓙ | CIRCLED LATIN SMALL LETTER J | |
| U+24DA | ⓚ | CIRCLED LATIN SMALL LETTER K | |
| U+24DB | ⓛ | CIRCLED LATIN SMALL LETTER L | |
| U+24DC | ⓜ | CIRCLED LATIN SMALL LETTER M | |
| U+24DD | ⓝ | CIRCLED LATIN SMALL LETTER N | |
| U+24DE | ⓞ | CIRCLED LATIN SMALL LETTER O | |
| U+24DF | ⓟ | CIRCLED LATIN SMALL LETTER P | |
| U+24E0 | ⓠ | CIRCLED LATIN SMALL LETTER Q | |
| U+24E1 | ⓡ | CIRCLED LATIN SMALL LETTER R | |
| U+24E2 | ⓢ | CIRCLED LATIN SMALL LETTER S | |
| U+24E3 | ⓣ | CIRCLED LATIN SMALL LETTER T | |
| U+24E4 | ⓤ | CIRCLED LATIN SMALL LETTER U | |
| U+24E5 | ⓥ | CIRCLED LATIN SMALL LETTER V | |
| U+24E6 | ⓦ | CIRCLED LATIN SMALL LETTER W | |
| U+24E7 | ⓧ | CIRCLED LATIN SMALL LETTER X | |
| U+24E8 | ⓨ | CIRCLED LATIN SMALL LETTER Y | |
| U+24E9 | ⓩ | CIRCLED LATIN SMALL LETTER Z | |
| 追加の丸囲み数字 | |||
| U+24EA | ⓪ | CIRCLED DIGIT ZERO | |
| 黒丸囲み白数字 | |||
| U+24EB | ⓫ | NEGATIVE CIRCLED NUMBER ELEVEN | |
| U+24EC | ⓬ | NEGATIVE CIRCLED NUMBER TWELVE | |
| U+24ED | ⓭ | NEGATIVE CIRCLED NUMBER THIRTEEN | |
| U+24EE | ⓮ | NEGATIVE CIRCLED NUMBER FOURTEEN | |
| U+24EF | ⓯ | NEGATIVE CIRCLED NUMBER FIFTEEN | |
| U+24F0 | ⓰ | NEGATIVE CIRCLED NUMBER SIXTEEN | |
| U+24F1 | ⓱ | NEGATIVE CIRCLED NUMBER SEVENTEEN | |
| U+24F2 | ⓲ | NEGATIVE CIRCLED NUMBER EIGHTEEN | |
| U+24F3 | ⓳ | NEGATIVE CIRCLED NUMBER NINETEEN | |
| U+24F4 | ⓴ | NEGATIVE CIRCLED NUMBER TWENTY | |
| 二重丸囲み数字 | |||
| U+24F5 | ⓵ | DOUBLE CIRCLED DIGIT ONE | |
| U+24F6 | ⓶ | DOUBLE CIRCLED DIGIT TWO | |
| U+24F7 | ⓷ | DOUBLE CIRCLED DIGIT THREE | |
| U+24F8 | ⓸ | DOUBLE CIRCLED DIGIT FOUR | |
| U+24F9 | ⓹ | DOUBLE CIRCLED DIGIT FIVE | |
| U+24FA | ⓺ | DOUBLE CIRCLED DIGIT SIX | |
| U+24FB | ⓻ | DOUBLE CIRCLED DIGIT SEVEN | |
| U+24FC | ⓼ | DOUBLE CIRCLED DIGIT EIGHT | |
| U+24FD | ⓽ | DOUBLE CIRCLED DIGIT NINE | |
| U+24FE | ⓾ | DOUBLE CIRCLED NUMBER TEN | |
| 追加の黒丸囲み白数字 | |||
| U+24FF | ⓿ | NEGATIVE CIRCLED DIGIT ZERO | |
小分類
このブロックの小分類は「丸囲み数字」(Circled numbers)、「括弧囲み数字」(Parenthesized numbers)、「ピリオド付き数字」(Numbers period)、「括弧囲みラテン文字」(Parenthesized Latin letters)、「丸囲みラテン文字」(Circled Latin letters)、「追加の丸囲み数字」(Additional circled number)、「黒丸囲み白数字」(White on black circled numbers)、「二重丸囲み数字」(Double circled numbers)、「追加の黒丸囲み白数字」(Additional white on black circled number)の9つとなっている[4]。
丸囲み数字(Circled numbers)
この小分類には丸で囲前れた数字が収録されている。
括弧囲み数字(Parenthesized numbers)
この小分類には括弧で囲まれた数字が収録されている。
ピリオド付き数字(Numbers period)
この小分類にはピリオドの付いた数字が収録されている。
U+1F100(囲み英数字補助ブロック)から始まる同様のシンボルも参照すること[4]。
括弧囲みラテン文字(Parenthesized Latin letters)
この小分類には括弧で囲まれたラテン文字が収録されている。
U+1F100から始まる大文字セットも参照すること。括弧で囲まれたラテン文字には大文字と小文字のマッピングは存在しない[4]。
丸囲みラテン文字(Circled Latin letters)
この小分類には丸で囲まれたラテン文字が収録されている。
追加の丸囲み数字(Additional circled number)
この小分類には丸囲みの0のみが収録されている。
黒丸囲み白数字(White on black circled numbers)
この小分類には黒い丸に囲まれた白い数字が収録されている。
二重丸囲み数字(Double circled numbers)
この小分類には二重丸に囲まれた数字が収録されている。
追加の黒丸囲み白数字(Additional white on black circled number)
この小分類には黒丸に囲まれた数字の0のみが収録されている。
文字コード表
| 囲み英数字(Enclosed Alphanumerics)[1] Official Unicode Consortium code chart (PDF) |
||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+246x | ① | ② | ③ | ④ | ⑤ | ⑥ | ⑦ | ⑧ | ⑨ | ⑩ | ⑪ | ⑫ | ⑬ | ⑭ | ⑮ | ⑯ |
| U+247x | ⑰ | ⑱ | ⑲ | ⑳ | ⑴ | ⑵ | ⑶ | ⑷ | ⑸ | ⑹ | ⑺ | ⑻ | ⑼ | ⑽ | ⑾ | ⑿ |
| U+248x | ⒀ | ⒁ | ⒂ | ⒃ | ⒄ | ⒅ | ⒆ | ⒇ | ⒈ | ⒉ | ⒊ | ⒋ | ⒌ | ⒍ | ⒎ | ⒏ |
| U+249x | ⒐ | ⒑ | ⒒ | ⒓ | ⒔ | ⒕ | ⒖ | ⒗ | ⒘ | ⒙ | ⒚ | ⒛ | ⒜ | ⒝ | ⒞ | ⒟ |
| U+24Ax | ⒠ | ⒡ | ⒢ | ⒣ | ⒤ | ⒥ | ⒦ | ⒧ | ⒨ | ⒩ | ⒪ | ⒫ | ⒬ | ⒭ | ⒮ | ⒯ |
| U+24Bx | ⒰ | ⒱ | ⒲ | ⒳ | ⒴ | ⒵ | Ⓐ | Ⓑ | Ⓒ | Ⓓ | Ⓔ | Ⓕ | Ⓖ | Ⓗ | Ⓘ | Ⓙ |
| U+24Cx | Ⓚ | Ⓛ | Ⓜ | Ⓝ | Ⓞ | Ⓟ | Ⓠ | Ⓡ | Ⓢ | Ⓣ | Ⓤ | Ⓥ | Ⓦ | Ⓧ | Ⓨ | Ⓩ |
| U+24Dx | ⓐ | ⓑ | ⓒ | ⓓ | ⓔ | ⓕ | ⓖ | ⓗ | ⓘ | ⓙ | ⓚ | ⓛ | ⓜ | ⓝ | ⓞ | ⓟ |
| U+24Ex | ⓠ | ⓡ | ⓢ | ⓣ | ⓤ | ⓥ | ⓦ | ⓧ | ⓨ | ⓩ | ⓪ | ⓫ | ⓬ | ⓭ | ⓮ | ⓯ |
| U+24Fx | ⓰ | ⓱ | ⓲ | ⓳ | ⓴ | ⓵ | ⓶ | ⓷ | ⓸ | ⓹ | ⓺ | ⓻ | ⓼ | ⓽ | ⓾ | ⓿ |
備考
|
||||||||||||||||
絵文字
このブロックには、1文字の絵文字(U+24C2)が収録されている[5][6]。これは丸囲みのMで、地下鉄(metro)を表す[7]。また、マスクワーク(半導体デバイスのチップ上の配置)を表す[8]。
この文字に対し2種類の異体字セレクタ、絵文字表示(U+FE0F VS16)かテキスト表示(U+FE0E VS15)が適用できる。デフォルトはテキスト表示である[9]。
| U+ | 24C2 |
| base code point | Ⓜ |
| base+VS15 (text) | Ⓜ︎ |
| base+VS16 (emoji) | Ⓜ️ |
履歴
以下の表に挙げられているUnicode関連のドキュメントには、このブロックの特定の文字を定義する目的とプロセスが記録されている。
| バージョン | コードポイント[a] | 文字数 | L2 ID | WG2 ID | ドキュメント |
|---|---|---|---|---|---|
| 1.0.0 | U+2460..24EA | 139 | (to be determined) | ||
| L2/11-438[b][c] | N4182 | Edberg, Peter (2011-12-22), Emoji Variation Sequences (Revision of L2/11-429) | |||
| 3.2 | U+24EB..24FE | 20 | L2/99-238 | Consolidated document containing 6 Japanese proposals, (1999-07-15) | |
| N2093 | Addition of medical symbols and enclosed numbers, (1999-09-13) | ||||
| 4.0 | U+24FF | 1 | L2/01-480 | Muller, Eric (2001-12-14), Proposal to add NEGATIVE CIRCLED DIGIT ZERO | |
| L2/02-193 | Muller, Eric (2001-12-14), Proposal to add Negative Circled Digit Zero | ||||
関連項目
- 囲み文字
- 著作権マーク、登録商標マーク、レコード著作権マークはこのブロックではないところで別に定義されている。
- en:Japanese rebus monogram(日本の判じ物モノグラム)
出典
- ^ “Unicode character database”. The Unicode Standard. 2016年7月9日閲覧。
- ^ “Enumerated Versions of The Unicode Standard”. The Unicode Standard. 2016年7月9日閲覧。
- ^ a b c d The Unicode Standard, 6.0.1
- ^ a b c “The Unicode Standard, Version 15.1 - U2460.pdf” (PDF). The Unicode Standard (英語). 2024年11月18日閲覧.
- ^ “UTR #51: Unicode Emoji”. Unicode Consortium (2016年11月22日). 2016年12月22日閲覧。
- ^ “UCD: Emoji Data for UTR #51”. Unicode Consortium (2016年11月14日). 2016年12月22日閲覧。
- ^ “Ⓜ️ Circled Latin Capital Letter M Emoji”. 2018年1月27日閲覧。
- ^ “Federal Statutory Protection for Mask Works (Copyright Circular 100)”. 合衆国著作権局. pp. 5 (2012年9月). 2014年3月22日閲覧。
- ^ “Unicode Character Database: Standardized Variation Sequences”. The Unicode Consortium. 2016年12月22日閲覧。
情報源
((ⅰ) から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2023/12/27 10:12 UTC 版)
情報源(じょうほうげん)には主に次の2つの意味がある。
- 情報の提供者、入手元、入手経路、発信源(ソース、英: information source)。例えば、歴史においては史料(英: historical source)、調査・研究においては資料(英: source text)。ジャーナリズムにおいては、取材源 (Journalism sourcing) 。
- 情報理論の概念。
情報の提供者、史料、資料
様々な情報源
情報源としては例えば次のようなものがある[1]。
- 書籍 - 書籍は一つのテーマを徹底的に論述し、しばしば歴史的な文脈の中で具体的な反論を提起しており有益である[1]。
- 定期刊行物 - 定期的に刊行されているもの。一般向けの定期刊行物もあるが、専門家向けの定期刊行物(専門誌)もある。季刊誌、月刊誌、週刊誌など。
- 新聞 - 議論の行う時にはしばしば最新の情報、タイムリーな情報が必要だが、新聞はそうした情報源として優れている[1]。
- 年鑑とデータブック - 具体的な統計を探すのに適しており、それを書籍で探すよりも時間の節約になることが多い[1]。
- 政府刊行物 - 政府側の見解や、政府が把握している情報を調べるのに適した情報源。委員会や公聴会などにおける専門家の発言などを知るのにも役立つことがある。
- 人物による口頭での発言、証言 - 裁判などでは人の証言が決定的な根拠となることも多い。
信頼性の検討
情報源に着目しつつ情報の内容を確認することによって、得られた情報の内容の信頼性を吟味することもできる。ひとつは、同じ情報源から得られる別の記述と整合性があるか、また、別の情報源から得られる記述・証言と整合性があるかを確かめる[1]。この2つの作業によって信頼性を吟味することができるのである[1]。ジーゲルミューラーは前者を「内的整合性」後者を「外的整合性」という用語で呼んでいる[1]。
同一の情報源からの情報でありながら別の箇所の記述と整合性を欠いている場合は、その情報源の信頼性に疑問符がつくことになる[1]。不整合があるということは、何らかの不注意や上滑りな分析がそこに含まれている可能性を示唆している[1]。
裁判においては検察官や弁護士は証人の発言の内的整合性に特に注意を払う[1]。内的整合性がない、との指摘で証人の発言内容の信頼性は下がってしまうのである[1]。 中絶を巡る議論でも、中絶賛成派が論拠に持ち出す話の内部整合性のなさが中絶反対派から批判されることがある[1]。母体の生命を保護するために中絶を認めるべきだとしておきながら胎児の生命は失っても問題ないとするのでは、生命の普遍性という観点からは内部整合性を欠いているのである[1]。
外部整合性について言うと、独立した、別々の情報源からの情報と整合性があるかどうかを調べてみる、ということである[1]。ある人の発言が他の様々な情報源の著しく食い違い支持者が全くない場合は、その発言を根拠としてしまうことには問題が出てくる[1]。ジーゲルミューラーによれば、複数の情報源で情報に食い違いがある場合でも、ただちに情報元の信頼性がすっかり失われてしまうわけではないが、問題となっている主題に関しては複数の情報元のどれがより信頼できるのか検討が必要となってくるという[1]。
外的整合性の有無は根拠を保証する肯定的な使い方も、根拠を拒否する否定的な使い方もできる[1]。歴史学者のルイ・ゴットシャルクは「独立的実証」という概念について次のように説明している[1]。「歴史学者が用いる一般的な規則というのは、二人以上の信頼できる証人の独立した証言に基づく事項だけを、歴史的なものとして受け入れることである」。二つの独立した(無関係な)情報源から同一の意見や前提が得られ、それを根拠として用いれば、より高い信頼性が得られるのである[1]。
情報理論
 |
この節は検証可能な参考文献や出典が全く示されていないか、不十分です。(2011年11月)
|
情報理論においては、情報源とはビット列(もしくはより一般になんらかのシンボルの有限列)が、選ばれるもととなる空間の事[要出典]。より厳密に言えば、シンボルの有限列全体の空間とその上の確率分布の組のこと。シンボルの有限列はその確率分布に従って選ばれる[要出典]。
代表的な情報源として次のものがある:
無記憶情報源とは、各シンボルが統計的に独立に発生する情報源である。この種の情報源は、各シンボルの生起確率 ![]()

-, -i(語幹変化なし)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2021/12/31 18:24 UTC 版)
「ラテン語の文法」の記事における「-, -i(語幹変化なし)」の解説
単数主格で語幹のみとなるパターンには、二通りある。このうち、語幹の変化のないものの格変化を、ここで示しておく。「少年」を意味する「puer, pueri」を例に挙げて、格変化を示そう。 数 (numerus)単数 (singularis)複数 (pluralis)主格 (nominativus) - (puer) -i (pueri) 属格 (genitivus) -i (pueri) -orum (puerorum) 与格 (dativus) -o (puero) -is (pueris) 対格 (accusativus) -um (puerum) -os (pueros) 奪格 (ablativus) -o (puero) -is (pueris) 呼格は、主格と同形である。 このパターンの格変化をする男性名詞gener, generi 婿 liberi, liberorum (pl.) 子供達 signifer, signiferi 旗手 socer, soceri 舅 vesper, vesperi 夕方 puer, pueri 少年 vir, viri 男、夫、立派な人物 triumvir, triumviri 三頭政治家 このパターンの格変化をする女性名詞 このパターンの格変化をする中性名詞
※この「-, -i(語幹変化なし)」の解説は、「ラテン語の文法」の解説の一部です。
「-, -i(語幹変化なし)」を含む「ラテン語の文法」の記事については、「ラテン語の文法」の概要を参照ください。
「I」の例文・使い方・用例・文例
- その患者はHIVウイルスを持っている
- 彼はFBIに雇用されている
- われわれの時代は情報技術,すなわちITが特色である
- FBIが調査に乗り出した
- FBI の諜報部員が彼の電話を盗聴し始めた
- FBIは連邦調査局のことである
- 子どもたちのIQをテストする
- エイズはHIVウイルスが原因だという学説
- という文は“I"のあとに“am"を補って考える
- プラスアルファとして、IT技術を獲得したい。
- 電車やバスを利用するためのICカードです。買い物にも使えます。
- バンクーバー― マレーシアに拠点を置くBaronホテルグループはHoward Hotels Internationalを買収する交渉を行っている。
- ITの専門技術を習得する
- さまざまな事業:Powersさんは、センターの青少年バスケットボールプログラムがBrookville Inquirer の記事内で最近、賞賛されたと知らせた。
- 会社の福利厚生の一部として、Adler Industriesの社員は、街のフィットネスセンターで会員権の割引を受ける権利があります。
- 先日は、Melodia Industriesの営業担当者の職にご応募いただき、ありがとうございます。
- 御社よりInglis博物館へ、引き続きご支援いただきありがとうございます。
- 博物館の後援者として、Commonwealth Industries社員の皆様は入場料が半額となります。
- HILL AND COMPANYは、ちょうど1 年前に創業し、誇りをもって、初の100 時間に及ぶセールを発表いたします。
- HILL特製のワインオープナーを1つ買うと、もう1つが無料
(ⅰ)と同じ種類の言葉
固有名詞の分類
「(ⅰ)」に関係したコラム
FXのチャート分析ソフトMT4で1つのチャート画面に2つの通貨ペアを表示するには
FX(外国為替証拠金取引)のチャート分析ソフトMT4(Meta Trader 4)では、1つのチャート画面に1つの通貨ペアのチャートが表示できます。2つの通貨ペアのチャートを見比べたい時には、2つのチ...
-
MT4(Meta Trader 4)でFXやCFDなどのチャートを表示して、1日ごとの相場の動きを一目でわかるようにするインディケーターを紹介します。インディケーターは「Coloured_Days_o...
-
FX(外国為替証拠金取引)のチャート分析ソフトMT4(Meta Trader 4)では、インディケーターを起動中にある数値に達した時にメール通知することができます。メール通知をするには、MT4でのメー...
FXのチャート分析ソフトMT4でサポートラインとレジスタンスラインを自動で表示するには
サポートラインとレジスタンスラインは、為替レートがレンジで推移している時にレンジの下限と上限に水平線を引いたもので、ブレイクアウトを見つけるために用いられます。FX(外国為替証拠金取引)のチャート分析...
FXのチャート分析ソフトMT4でゴールデンクロス、デッドクロスに矢印のマークを付けるには
ゴールデンクロスとは、短期の移動平均線が、長期の移動平均線を下から上へ突き抜けた状態のことです。ゴールデンクロスは、買いのエントリーポイントになります。デッドクロスとは、短期の移動平均線が、長期の移動...
FXのチャート分析ソフトMT4で高値と安値のラインを引くには
FX(外国為替証拠金取引)のチャート分析ソフトMT4(Meta Trader 4)で高値と安値のラインを引く方法を紹介します。高値のラインは、ローソクの高値の1本1本を線で結んだものになります。同じく...
- (ⅰ)のページへのリンク
辞書ショートカット
カテゴリ一覧
すべての辞書の索引
「(ⅰ)」の関連用語
(ⅰ)のページの著作権
Weblio 辞書
情報提供元は
参加元一覧
にて確認できます。
| Copyright © 2025実用日本語表現辞典 All Rights Reserved. | |
|
(C)Shogakukan Inc. 株式会社 小学館 |
|
| (c) 2025 Mitsubishi Motors Corporation. All rights reserved. | |
| All Rights Reserved, Copyright © Japan Science and Technology Agency | |
| Copyright (C) 2025 NII,NIG,TUS. All Rights Reserved. | |
|
Bio Wikiの記事を複製・再配布した「分子生物学用語集」の内容は、特に明示されていない限り、次のライセンスに従います: CC Attribution-Noncommercial-Share Alike 3.0 Unported |
|
| Copyright (C) 2025 株式会社皓星社 All rights reserved. | |
|
All text is available under the terms of the GNU Free Documentation License. この記事は、ウィキペディアのI (改訂履歴)、ローマ数字 (改訂履歴)、囲み英数字 (改訂履歴)、情報源 (改訂履歴)の記事を複製、再配布したものにあたり、GNU Free Documentation Licenseというライセンスの下で提供されています。 Weblio辞書に掲載されているウィキペディアの記事も、全てGNU Free Documentation Licenseの元に提供されております。 |
|
|
Text is available under GNU Free Documentation License (GFDL). Weblio辞書に掲載されている「ウィキペディア小見出し辞書」の記事は、Wikipediaのラテン語の文法 (改訂履歴)、lsof (改訂履歴)、トリプル・クァルテット (改訂履歴)、惑星連邦 (改訂履歴)、マリオペイント (改訂履歴)、規格品番の販社コード一覧 (改訂履歴)、技術略語一覧 (改訂履歴)、法学のラテン語成句の一覧 (改訂履歴)、化学略語一覧 (改訂履歴)、ネットレーベル一覧 (改訂履歴)、鈴木治行 (改訂履歴)、疫学における区画モデル (改訂履歴)、ニュース番組一覧 (改訂履歴)、闘神都市 (改訂履歴)、フロイド・ローズ (改訂履歴)、雷の戦士ライディ (改訂履歴)、グラディウスNEO (改訂履歴)、Z -ツェット- (改訂履歴)、ローグ (改訂履歴)、HTML要素 (改訂履歴)、ダリウス・ミヨー (改訂履歴)、ゾーク (改訂履歴)の記事を複製、再配布したものにあたり、GNU Free Documentation Licenseというライセンスの下で提供されています。 |
|
Tanaka Corpusのコンテンツは、特に明示されている場合を除いて、次のライセンスに従います: Creative Commons Attribution (CC-BY) 2.0 France. Creative Commons Attribution (CC-BY) 2.0 France. | |
| この対訳データはCreative Commons Attribution 3.0 Unportedでライセンスされています。 | |
 | Copyright © 1995-2025 Hamajima Shoten, Publishers. All rights reserved. |
|
|
Copyright © Benesse Holdings, Inc. All rights reserved. |
|
|
Copyright (c) 1995-2025 Kenkyusha Co., Ltd. All rights reserved. |
|
|
日本語ワードネット1.1版 (C) 情報通信研究機構, 2009-2010 License All rights reserved. WordNet 3.0 Copyright 2006 by Princeton University. All rights reserved. License |
|
|
Copyright (C) 1994- Nichigai Associates, Inc., All rights reserved. 「斎藤和英大辞典」斎藤秀三郎著、日外アソシエーツ辞書編集部編 |
|
|
This page uses the JMdict dictionary files. These files are the property of the Electronic Dictionary Research and Development Group, and are used in conformance with the Group's licence. |
ビジネス|業界用語|コンピュータ|電車|自動車・バイク|船|工学|建築・不動産|学問
文化|生活|ヘルスケア|趣味|スポーツ|生物|食品|人名|方言|辞書・百科事典
|
ご利用にあたって
|
便利な機能
|
お問合せ・ご要望
|
会社概要
|
ウェブリオのサービス
|
©2025 GRAS Group, Inc.RSS
