データマイニング
データマイニング
データマイニング
データ・マイニング data mining
データマイニング
データマイニングとは、データベースに蓄積されている大量のデータから、統計や決定木などを駆使して、マーケティングに必要な傾向やパターンなどの隠された規則性、関係性、仮説を導き出す手法のことである。マイニング(mining)とは「採鉱」を意味するもので、いわば眠っている金脈を探り当てることになぞらえられている。
一見無秩序・無関係に見えるデータの山も、着眼点次第では各事項の間に有益な連関が見えてくることが少なくない。例えば、ある商店ではサングラスを買う人の多くが一緒にガムを買っているという事実が見つかるかも知れない。あるいは他の店舗では、曇りがちの日には生魚の売り上げが伸びているかもしれない。こうした連関を実績として見出すことによって、サングラスの陳列棚の近くにガムを配置する、とか、雲の多い日に鮮魚のセールを実施するとか、効果的なマーケティングを行うことができる。
データマイニングは、データベースの発展を中心とした情報技術の向上によって盛んに行われるようになった手法であるといえる。元となるデータが多ければ多いほど、処理作業は膨大なものになるが、実証性は高くなる。既存データを専用のデータベースに取り込んで意思決定に活用するシステムはデータウェアハウスと呼ばれるが、データウェアハウスは一個のデータマイニングツールであるといえる。
| マーケティング: | ソーシャルコマース ステップメール ステルスマーケティング データマイニング 電子クーポン ティーザーサイト データベースマーケティング |
データマイニング
【英】:data mining
概要
データベースに蓄えられた多量のデータから, 機械学習(machine learning)や統計的手法(statistical method)を用いて データの中に含まれる知識を発掘する手法をいう. 知識発見プロセスとしての, データ獲得,選択,前処理,変換,知識発見アルゴリズムの適用,解釈,評価といった 一連のサイクルを指す. 獲得した知識に基づく意思決定が目的であり, データ収集,発掘,評価といった人間と計算機の共同作業を伴う知識マネジメントとして捉えられる.
詳説
データマイニング (data mining)は, データベース (data base) [5] に蓄えられた大量の生データに対して, 機械学習 (machine learning)に関連する複数の手順を用いる戦略により, データに内在する規則性 (regularity), 制約 (constraint), ルール (rule)などを効率よく求める研究である. なお, データベースからの知識発見 (KDD: knowledge discovery in databases)とも呼ばれ, 知識発見 (knowledge discovery)に関わる多数の学習アルゴリズムが, 人工知能だけでなくデータベースや統計学の側面を含めて研究されている. まず, ノイズや例外を含み疎な構造をもつことも多い生データを対象としたデー タマイニングに共通する知識発見の手順を(1)~(6)に簡単に示す [1].
【手順】
(1)対象となるデータに対する既知の性質(背景知識)を利用してデータ収集を行い, データベースやデータウェアハウス (data warehouse)に格納する. (2)データに対する選択操作を前処理として行う. この段階はデータクリーニングと呼ばれる. (3)実装を前提とする制約のもとでデータの次元低減などによる変形操作を行う. (4)データマイニングを行うアルゴリズムを実行する. (5)導出された記述の解釈, ならびに, 記述の妥当性の検証を後処理として行う. (6)最終的な記述が評価され, 知識となる.
手順(4)のアルゴリズムで求まる知識の表現法によって, データの統計的解析 (statistical analysis of data)とデータの論理的解析 (logical analysis of data)の二種類に大きく分類される.
データの論理的解析の一種である決定木 (decision tree)を図1に示す. なお, 決定木を求めるアルゴリズムとしてID3 [4] などが知られており, エントロピーやMDL(minimum description length)基準が記述を選択する際に用いられる.
|
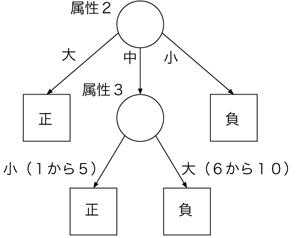 | |||||||||||||||||||||||||||||||||||||||||||||
図1: 決定木を用いた概念学習の一例 | ||||||||||||||||||||||||||||||||||||||||||||||
関係データベースの問合せ言語SQLのGroupBy操作の拡張として位置付けられる結合ルール (association rule)を求めるアルゴリズムの研究も数多い. 結合ルールを求めるために, 最小サポート(support)値と最小確信度(confidence)を定めるヒューリスティックな閾値が用いられる. なお, 最小閾値により多数のルール導出を制限するだけではなく, 新規性や興味深さの弱いルールを最大閾値で抑制することもある. また, 頻度の高い購買パターンを結合ルールが表すため, データベースマーケティング(database marketing)などをターゲットに, 計算機アーキテクチャを含めた効率良い実装が進んでいる.
その他, 多変量解析の手法を用いるクラスター分析 (cluster analysis)や, 因果関係を表現するベイズネットワーク (Baysian network)や, 論理的表現に対する帰納推論プログラミング(ILP: inductive logicprogramminge)などもアプローチの一つである. また, ルールの理解可能性を高める上で, ルールの視覚化 (visualization)も欠かせない.
なお, ラフ集合(rough sets), ファジー理論(fuzzy theory), ニューラルネットワーク(neural network), 遺伝アルゴリズム(genetic algorithm)などの研究とも密接に関係している.
ところで, データマイニングの対象となるデータは, 航空会社, 銀行, クレジットカード会社, 電話, 保険などでのトランザクションだけではなく, WWWデータや医療データなどの異なる性質をもつデータも含まれる [2]. 特に, 学習データの種類が限定される場合, 地理データに対しては空間データマイニング(spatial data mining), 文書データに対してはテキストマイニング(text mining)などと呼ぶ. また, データマイニングに関連したシフトウェア(siftware)と呼ばれるソフトウェアの開発も盛んである.
なお, 良質な知識を発見するには, 複数のアルゴリズムを適用するだけではなく, データの前処理・ルールの後処理が重要となる. したがって, 実用化に向けて, 例えば, 各種情報システムを効果的に運用することを考えたデータ収集戦略を決定しなければならない.
[1] U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth and R. Uthurusamy, Advances in Knowledge Discovery and Data Mining, AAAI/MIT Press, 1996.
[2] R. Michalski, I. Bratko and M. Kubat, Machine Learning and Data Mining, Methods and Applications, John Wiley & Sons Ltd., 1998.
[3] J. Pearl, Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference, Morgan-Kaufmann, 1988.
[4] J. R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann Publishers, Inc., 1993. 古川康一監訳, 『AIによるデータ解析』, トッパン, 1995.
[5] J. D. Ullman, Principles of Database and Knowledge-Base Systems, Vol.I, Vol.II, Computer Science Press, 1988.
| システム分析・意思決定支援・特許: | データウェアハウス データベース データベース管理 データマイニング トレードオフ分析 ハードシステム思考 ブレーンストーミング |
| 近似・知能・感覚的手法: | ソフトコンピューティング タブー探索 デンプスター・シェファーの証拠理論 データマイニング ナップサック問題 ニューラルネットワーク ニューラルネットワークによる学習 |
データマイニング
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/06/26 01:01 UTC 版)

|
この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。 (2018年11月)
|
| 機械学習および データマイニング |
|---|
 |
| |
データマイニング(英語: data mining)は、統計学、パターン認識、人工知能等のデータ解析の技法を大量のデータに網羅的に適用することで知識を取り出す技術のこと。DMと略して呼ばれる事もある。
通常のデータの扱い方からは想像が及びにくい、ヒューリスティク(heuristic、発見的)な知識獲得が可能であるという期待を含意していることが多い。とくにテキストを対象とするものをテキストマイニング、そのなかでもウェブページを対象にしたものをウェブマイニングと呼ぶ。英語では"data mining"の語の直接の起源となった研究分野であるknowledge-discovery in databases(データベースからの知識発見)の頭文字をとってKDDとも呼ばれる。
定義
データマイニングの定義としては、「明示されておらず今まで知られていなかったが、役立つ可能性があり、かつ、自明でない情報をデータから抽出すること」[1]、「データの巨大集合やデータベースから有用な情報を抽出する技術体系」[2]などがある。 データマイニングは、通常はデータの解析に関する用語として用いられるが、人工知能という用語などと同様、包括的な用語であり、様々な文脈において多様な意味で用いられる。
歴史
概説
1989年に起きた"Knowledge Discovery in Databases"と呼ばれる学術研究分野の確立が、データマイニングという研究分野の直接の起源である。データマイニングの発展には、1990年以降の計算機の性能向上や大量のデータ蓄積が可能となったことが直接的に関係している。デジタル形式でのデータの収集は、コンピュータを用いてデータ解析をすることを念頭に置いて1960年代には既に行われつつあった。関係データベースとその操作用の言語SQLが1980年代に出現し、オンデマンドで動的なデータ解析が可能となった。1990年代に至り、データ量は爆発的に増大した。データウェアハウスがデータの蓄積に用いられ始めた。これに伴い、データベースにおける大量データを処理するための手法としてデータマイニングの概念が現れ、統計解析の手法や人工知能分野での検索技術等が応用されるようになった。2010年代には膨大なデータを利用してデータマイニングを行うビッグデータ解析を用いた実用的なサービスが多数登場して提供されている。
1960年代
メインフレームが金融企業の基幹業務システムとして稼働開始した。同時に、デジタルデータの収集、蓄積、利用の試みが開始された。
1970年代
1971年から1973年にかけて、チリでサイバーシン計画が実行される。コントロールセンターが、テレックスを介して実時間でチリ各地に点在する工場からデータを収集して、収集したデータを元に、オペレーションズ・リサーチを用いて最適化した生産計画を作成し、工場に対して生産計画をフィードバックするシステムであった。
論文上で"Data mining"という語の使用が行われる。但し、語の定義は現在とは大きく異なっており、1970年代においては否定的なニュアンスで使用されている。
1980年代
現在の"Data mining"の定義と類似する"Knowledge Discovery in Databases"という語が出現する。関係データベースシステムとその操作用言語であるSQLが出現する。データウェアハウスの運用が開始される。
- 1989年 - "IJCAI'89 Workshop on Knowledge Discovery in Databases"という名称のワークショップがアメリカのデトロイトにおいて開催される。ここで"Knowledge Discovery in Databases"という語が初めて現れている。"Data mining"の語は既にデータベースの関係者の間で否定的な意味で用いられており、商標にも類似していたため、このような名称となった[注釈 1]。
1990年代
1990年頃から始まった計算機の急激な性能向上により"Knowledge Discovery in Databases"の研究が大幅に加速される。
- 1990年 - 1994年 - "Knowledge Discovery in Databases"の研究が推進される。この時点では研究者間でも同分野に対する認識は「データに対して何らかの演算を行って知識を発見する」といった程度のものであった。
- 1995年 - モントリオール国際会議において"Knowledge Discovery in Databases"の語の公認がなされる。
- 1996年 - "Knowledge Discovery and Data Mining: Towards a Unifying Framework."という論文が提出され、"Knowledge Discovery in Databases"と結び付けた形で"Data mining"の語の定義・基本機能・処理手順が提案される。同年より多数の研究者により本論文の引用が始まり、"Data mining"の語が論文上に頻出するようになる。この時点でデータマイニングという研究分野が明確に定義された。
- 1999年 - 2010年代に大量の実世界データを収集・供給する基盤となるInternet of Things(IoT)の用語がKevin Ashtonにより初めて使用された[注釈 2]。
2000年代
インターネットへの常時接続が一般家庭にも普及する。インターネット上に蓄積されたデータが加速度的に増加する。後にデータの主要な供給源の1つとなる友人紹介型のソーシャル・ネットワーキング・サービスが2002年より相次いで提供され始める。コンピュータとインターネットの普及に着目し、ビジネスにおいて膨大に蓄積され活用しきれなくなったデータの分析を専門に行う企業も徐々に出現し始める。
- 2000年 - "Knowledge discovery in databases: 10 years after"という論文が提出される。"Knowledge Discovery in Databases"の研究分野の創出より約10年後から"Knowledge Discovery in Databases"という研究分野の発展の歴史を振り返った内容となっている。
2010年代
英国"The Economist"誌において"big data"の語が提唱された。コモディティ化によりコンピュータの計算能力が安価になり、高速データ処理用のコンピュータ・クラスタの構築が容易にできるようになった。データ分析のコストが下がり、ビッグデータ解析の応用が進むようになった。データサイエンティストという名称の職業が台頭し始めた。また、ビッグデータを用いたデータマイニングを応用したサービスが一般向けにも提供され始めた。コグニティブ・コンピューティング・システムが商用で実用化された。テレビ番組の紹介コーナーでも、インターネット上に存在するビッグデータの統計分析結果を元に流行のトレンドを紹介するようになった。
ディープラーニングの実用化が急速に進み、非常に多数の人工知能サービスが現れた。
- 2010年 - 英国"The Economist"誌において"big data"の語が初めて現れる。
- 2011年2月16日 - データマイニングと推論を応用した質問応答システムである"IBM Watson"がアメリカのクイズ番組"Jeopady!"に出場して人間に勝利する[注釈 3]。
- 2012年 - メーカー系大手ITベンダーのビッグデータを扱うソリューションの事業化への取り組みが活発化する。
- 2016年2月18日 - "IBM Watson"の日本語学習が完了し、IBMが以前から予定していた日本語版のコグニティブ・コンピューティング・サービスの提供を開始した。
解析手法
頻出パターン抽出
データ集合の中から,高頻度で発生する特徴的なパターンを見つける。
- 相関ルール抽出
- その他の頻出パターン
- 時系列やグラフを対象としたものもある
クラス分類
クラス分類は与えられたデータに対応するカテゴリを予測する問題。
- 代表的な手法:単純ベイズ分類器, 決定木, サポートベクターマシン
- 例:薬品の化合物のデータから,その化合物に薬効がある・ないといったカテゴリを予測
回帰分析
与えられたデータに対応する実数値を予測する問題
- 代表的な手法:線形回帰、ロジスティック回帰、サポートベクトル回帰
- 例:曜日、降水確率、今日の売上げなどのデータを元に、明日の売上げという実数値データを予測
- 例:温度,水分活性,pHなどのデータを元に、食中毒細菌の増殖および死滅を予測[3]
クラスタリン グ
データの集合をクラスタと呼ぶグループに分ける。クラスタとは、同じクラスタのデータならば互いに似ていて、違うクラスタならば似ていないようなデータの集まり。
- データ・クラスタリングを参照
- 例:Webの閲覧パターンのデータから、類似したものをまとめることで、閲覧の傾向が同じ利用者のグループを発見する。
ソフトウェア
商業ソフトウェア
- SAS Enterprise Miner
- SPSS Clementine
- NAG NAG data Mining component
- NTTデータ数理システム Visual Mining Studio: 数理最適化を専門とする日本企業の製品である。
- KXEN,Inc. KXEN
- Rapid-I GmbH Rapid Miner
- TIBCO Spotfire: CIA開発ともいわれる米国政府機関御用達のマイニングツール。
- CART (HULINKS): 巨大な2進木でも短時間で作成可能な決定木解析ソフト。
- RandomForests (HULINKS): CARTとブートストラップ法で決定木の群体を複合生成するRandom forestを商用化したマイニングシステム。
- Data Mining (Oracle Data Mining): Oracle Database Enterprise EditionのオプションAPI。自動的にマイニングして予測・発見を報告する機能を開発しOracleアプリケーションに組み込むことを支援する。
- Data Robot ([1]) 複数のアルゴリズムを並列計算させ、評価関数で順位付けする。
無償ソフトウェア
- GNU R (r-project.org):GNUプロジェクトによるS言語仕様をGNU GPL実装した汎用統計可視化環境。一般的に"R言語"や"R"とも呼ばれる。無償の貢献プログラムパッケージは6000を越え、Wekaを利用するRwekaやRandom forestなどもある。UIは、R GUIかターミナル経由のコマンドライン入力のみ。下記RED Rなどの援用でダイアグラム入力も出来る。R自体はインタプリタだが、速度が必要ならC言語やFortranのコードを直接記述してコンパイル実行でき、パッケージRcpp併用でC++も混在可能。信頼性に定評があり、米国FDA公認。マルチプラットフォーム。GNU GPLオープンソース。
- Weka (waikato.ac.nz/ml/weka):ワイカト大学で開発された、javaベースのデータマイニングソフトウェア。ダイアグラムなど多様なグラフィカルインタフェースで高度なマイニング手法を視覚的に構築し駆使できる。連関規則やニューラルネットワーク、SVM、決定木などさまざまな分析手法があらかじめ数多くモジュールとして組み込まれており、コードを書く事なくモジュールをリンクで結んでいけば入力・分析・出力までの流れを構築できる。ゼロからコードを書いてモジュール登録もできる他、プラグインによる機能拡張も可能。ただデータマイニング研究用のツールとして産まれただけに、的確に使うには分析手法の専門的な評価知識が必要。GNU GPLオープンソース。
- RapidMinerコミュニティ版 (rapid-i-partner.jp/product/miner):上記商用エンタープライズ版からサポートサービスなどを除いたフリー版。オープンソース。内部にWekaを統合し、Weka同様にダイアグラム式の分析フローを構築できる。GNU Rへのインタフェースもある。
- Julia (プログラミング言語) (julialang.org):科学技術計算を主たる目的として設計された汎用高水準プログラミング言語とその実行環境。その開発動機として「R言語の柔軟性は良いが、処理速度に幻滅した」ことを上げ、高速処理を開発の最優先目標としている。公式ページには既に統計やマイニングに適用できる多数の分野別パッケージが公開されている。LLVMを利用しており、移植性にも優れる。MIT License オープンソース。
- Orange (orange.biolab.si):グラフィカルデータマイニングソフトウェア。コードを書かなくともモジュールをダイアグラムで結んでいけば分析フローを構築できる。Pythonで書かれている。Windows,OSX,各種Linux対応のマルチプラットフォーム。GNU GPLオープンソース。
- Red-R (red-r.org):GNU Rにダイアグラムインタフェースを統合できるソフトウェア。フロントエンドにOrangeを利用しているためOrangeと同一の感覚でRを使えるばかりか、GNU Rの既存のコードとダイアグラムを相互に変換できる。GNU GPLオープンソース。
- R AnalyticFlow (ef-prime.com):GNU Rにダイアグラムインタフェースを統合できるソフトウェア。GNU Rの既存のコードとダイアグラムを相互に変換できる。RED Rに比べ、新規の分析フロー開発を重視した機能が充実している。日本の企業ef-primeが無料で配布しているので日本語マニュアルがあり、有償の法人サポートもある。RjpWikiにはユーザーコミュニーティがある。
- D3.js (d3js.org): ブラウザを使って統計データを様々な表現で可視化するための JavaScriptライブラリ。
- OpenCV:イメージや形状データの認識・抽出・予測処理を目的としたコンピュータビジョンライブラリであるが、パターン認識、機械学習など汎用性ある関数が数多く収録され、データマイニングでの可用性も高い。インテルが開発。オープンソース。
- Shogun toolbox (Shogun): マルチカーネル学習(MKL)などサポートベクターマシンを中心として最先端のアルゴリズムを網羅した機械学習ツールボックス。C++で実装され、MATLAB、GNU R、GNU Octave、Python、Java、Lua、Ruby、C# から利用可能なインタフェースがある。GNU GPL3。
脚注
注釈
- ^ "IJCAI'89 Workshop on Knowledge Discovery in Databases"は、"Expert Database Systems, Scientific Discovery, Fuzzy Rules, Using Domain Knowledge, Learning from Relational (Structured) Data, Dealing with Text and other Complex Data, Discovery Tools, Better Presentation Methods, Integrated Systems, Privacy"の9分野の研究成果が発表された大規模なワークショップである。
- ^ この当時のIoTは、様々な物体にRFIDタグを貼り付け、RFIDに対応したセンサーを用いて物体からの情報収集を行い、収集した情報を活用することを指していた。
- ^ 後にコグニティブ・コンピューティング・システムとして初の商用の実用化を達成する。
出典
- ^ W. Frawley and G. Piatetsky-Shapiro and C. Matheus, Knowledge Discovery in Databases: An Overview. AI Magazine, Fall 1992, pp. 213-228.
- ^ D. Hand, H. Mannila, P. Smyth: Principles of Data Mining. MIT Press, Cambridge, MA, 2001. ISBN 0-262-08290-X (各データマイニング手法の理論背景などが中心)
- ^ Hiura, Satoko; Koseki, Shige; Koyama, Kento (2021-12). “Prediction of population behavior of Listeria monocytogenes in food using machine learning and a microbial growth and survival database” (英語). Scientific Reports 11 (1): 10613. doi:10.1038/s41598-021-90164-z. ISSN 2045-2322. PMC 8134468. PMID 34012066.
参考文献
- Jiawei Han and Micheline Kamber "Data Mining: Concepts and Techniques," Morgan Kaufmann, second edition, 2006, ISBN 978-1558609013(何でも載っている百科事典的な本)
- Ian H. Witten and Eibe Frank, "Data Mining: Practical Machine Learning Tools and Techniques," Elsevier, second edition, 2005, ISBN 978-0120884070(いろいろな手法の利用法とフリーのツールWekaのチュートリアル)
- Chandrika Kamath: "Scientific Data Mining: A Practical Perspective", SIAM, ISBN 978-0-898716-75-7(2009年)。
- Trevor Hastie、Robert Tibshirani and Jerome Friedman: The Elements of Statistical Learning: Data Mining, Inference, and Prediction(2nd Ed.), Springer, 978-0-387-84858-7(2017).
- 邦訳:「統計的学習の基礎:データマイニング・推論・予測」、共立出版、ISBN 978-4-320-12362-5 (2014年6月25日).
- 元田浩、津本周作、山口高平、沼尾正行「データマイニングの基礎」オーム社, 2006, ISBN 978-4274203480(初学者向けで全体を俯瞰できる本)
- 福田剛志、森本康彦、徳山豪著「データマイニング」共立出版, 2001.9, ISBN 4-320-12002-7(相関ルール抽出について詳しい)
- 山西健司:「情報論的学習とデータマイニング」、朝倉書店、ISBN 978-4254116830(2014年4月28日)。
- Trevor Hastie、Robert Tibshirani、Jerome Friedman:「統計的学習の基礎:データマイニング・推論・予測」、共立出版、ISBN 978-4-320-12362-5(2014年6月25日)。
- Anand Rajaraman, Jeffrey David Ullman, 岩野和生(訳)、浦本直彦(訳):「大規模データのマイニング」、共立出版、ISBN 978-4320123755(2014年7月25日)。
関連項目
外部リンク
- 電子情報通信学会 情報論的学習理論と機械学習 (IBISML) 研究会
- 朱鷺の杜Wiki - 機械学習やデータマイニングについてのWiki
- Data Mining Program, University of Central Florida
- データマイニング入門 - 東京大学
- 『データマイニング』 - コトバンク
|
|
|
|---|---|
| ハードウェア | |
| コンピュータシステムの構造 | |
| ネットワーク |
|
| ソフトウェアの構造 | |
| ソフトウェア記法 とツール |
|
| ソフトウェア開発 |
|
| 計算理論 | |
| アルゴリズム | |
| コンピューティングの数学 | |
| 情報システム |
|
| セキュリティ |
|
| ヒューマンコンピュータ インタラクション |
|
| 並行性 | |
| 人工知能 |
|
| 機械学習 | |
| グラフィックス | |
| 応用コンピューティング | |


データマイニング
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2021/08/07 03:58 UTC 版)
「ナレッジマネジメント」の記事における「データマイニング」の解説
データマイニング(data mining)とは、人工知能や統計学を利用してデータから知識を取り出そうとする試み。主に共起現象を探り、セールスに結びつけようとしている。 例1:スーパーでビデオとガムが共に売れる → 両者を同じ場所に置く。 例2:本Aを買う人は、後に本Bを買うことが多い → 購入者に本Bを薦めるダイレクトメールを送る。 従来の統計学と大差ないが、POSやオンラインショッピングによる大量のITデータの中から法則性を見つけ出すことに主眼が置かれている。
※この「データマイニング」の解説は、「ナレッジマネジメント」の解説の一部です。
「データマイニング」を含む「ナレッジマネジメント」の記事については、「ナレッジマネジメント」の概要を参照ください。
固有名詞の分類
- データマイニングのページへのリンク
