多変量解析
多変量解析 multi-variate analysis
多変量解析
複数の特性値に対してデータの特徴を要約し、目的に応じたデータの統合化を行う手法。いろいろな手法があるが、主成分解析がもっともよく知られている。多くの因子のなかから要因となるものを知ることができる。
多変量解析
【英】:multivariate analysis
概要
解析の対象に対して, 複数の変数(特性)についての値が得られているときに, それらを用いて, 総合的に解析するのを多変量解析という. 変数の型および変数の扱い方により, 種々の解析方法がある. 主成分分析や因子分析のように, すべての変数を同じに扱う場合と, 回帰分析のように, 変数を2つのグループに分けて, 一方で他方を説明する場合がある.
詳説
解析の対象 (会社, 地域, 人など) に対して, 複数の変数 (特性) についての値が得られているときに, それらを用いて, 総合的に解析するのを多変量解析という. 変数の型および変数の扱い方により, 種々の解析方法がある.
変数の型は, 同異だけがわかる名義尺度変数 (質的変数) と差に意味がある間隔尺度変数 (量的変数) に分かれる. 会社名, 地名, 人名などは, 名義尺度変数である. 名義尺度変数は, 分類にしか使えないが, 複数の間隔尺度変数は, 重み(係数)を乗じて, 加えた関数を考えることができる.
変数の扱い方には, すべての変数を同じに扱う場合と二つに分ける場合がある. 後者では, 第1のグループの変数の関数と第2のグループの変数の対応を求める. 第1のグループの変数を説明変数, 第2のグループの変数を目的変数という. 目的変数は, 1個であることが多い.
すべての変数が名義尺度変数である場合は, 対象を多重に分類した分割表を解析する方法があるが, 通常は, 多変量解析の対象にしていないので, ここでは, すべての変数が間隔尺度変数であるとする.
元の変数との関係をできるだけ失わないようにして, より少数の総合特性値をいくつか求める方法として, 主成分分析や因子分析がある. 主成分分析では, 主成分といわれる元の変数の線形式を順次一つずつ求めていく. したがって, 第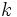 (≧2)主成分には, すでに定まっている第1から第
(≧2)主成分には, すでに定まっている第1から第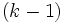 主成分までに追加するのに最適なものが選ばれる. しかし, とりあげる総合特性値の数が予め定まっている場合は, 第1主成分から第主成分の1次変換であれば, どれでもよいので, 意味を考えて, よりよい個の因子と呼ばれる総合特性値を求めるのが因子分析である.
主成分までに追加するのに最適なものが選ばれる. しかし, とりあげる総合特性値の数が予め定まっている場合は, 第1主成分から第主成分の1次変換であれば, どれでもよいので, 意味を考えて, よりよい個の因子と呼ばれる総合特性値を求めるのが因子分析である.
対象をいくつかのグループに分類する方法として, クラスター分析がある.
説明変数は, すべて間隔尺度変数であるとする. 目的変数との関係がある説明変数の関数を求める方法がいくつか考えられている.
目的変数によって対象をグループ分けしたとき, 同じグループ内では近い値をとり, 異なるグループでは離れた値をとる説明変数の関数が求められれば, 説明変数で目的変数を判別することができる. 目的変数を判別するために用いる説明変数の関数を判別関数という.
その値が目的変数の値とできるだけ近くなるような説明変数の関数を求める方法として, 回帰分析がある.
ある特徴の有無, 質問の肯定・否定による回答などのように, 二つに分けられる名義尺度変数は, 0か1の値をとる0-1変数におきかえることで, 間隔尺度変数のように扱うことができる. 一般に, 個に分ける名義尺度変数は, 個の0-1変数に置き換えることができる.
0-1変数だけの多変量解析として, 各種の数量化法が提案されている.
順序だけ意味がある順序尺度変数は, 点数化によって, 間隔尺度変数にできる. たとえば, 品物に松, 竹, 梅のランクが付けられている場合, それぞれに, 3, 2, 1や5, 2, 1の数値を対応させれば, 間隔尺度変数として扱うことができる. なお, 順序尺度変数は, 順位相関係数を用いて, 解析することもできる.
比が意味を持つ比尺度変数は, その対数をとることによって, 間隔尺度変数になる.
複数の変数を扱うとき, 単位に注意する必要がある. 単位がすべて同じであれば, ほとんど問題がないが, 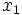 の単位はm,
の単位はm, 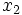 はcm,
はcm, 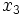 はgのように, 異なるときは, 重み (係数)
はgのように, 異なるときは, 重み (係数) 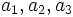 の単位を変えることによって, 重み付きの和
の単位を変えることによって, 重み付きの和
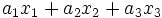
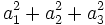
多変量解析では, 単位を揃えることとばらつきを揃えることを兼ねて, 初めにその変数の標準偏差で割る変数変換がよく行われる.
多変量解析
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2026/03/31 04:50 UTC 版)

|
|
この項目「多変量解析」は加筆依頼に出されており、内容をより充実させるために次の点に関する加筆が求められています。
加筆の要点 - 統計学の分野の内容をベースとした導入部分の出典明記・加筆など。また、各学問での多変量解析の利用など。 (貼付後はWikipedia:加筆依頼のページに依頼内容を記述してください。記述が無いとタグは除去されます) (2020年7月) |
多変量解析(たへんりょうかいせき、英語: multivariate analysis、略:MVA)は、多変量統計の原則に基づき、一つの対象に対して行われた「複数の測定値」を同時に扱う統計手法である。単一のデータを見るのではなく、それら複数の測定値の間にどのような関係性や構造があるのかを明らかにすることを主目的とする。
当初は統計学の理論として生まれたが、コンピュータの発展とともに他の分野でも応用されるようになっていった[1]。
現代における主要な活用領域は、大きく以下の4つに分類される[2]。
- モデルと分布の解析: 複雑な変数の集まりがどのような法則で分布しているかを分析する。
- 関係性の測定: 変数同士がどのように影響し合っているかを数値化する。
- 多次元領域の確率計算: 多くの条件が絡み合う中での発生確率を算出する。
- データ構造とパターンの探索:膨大なデータの中に潜むパターンやグループを見つけ出す。
この多変量解析を、物理法則に基づくシミュレーション(物理ベース解析)に適用しようとすると、計算が非常に複雑になる。特に、複数のシステムが階層的に組み合わさった大規模な対象を扱う場合、変数の数(次元数)が増えるにつれて計算量が爆発的に増加し、解析が行き詰まることがしばしばある。これを一般に「次元の問題」と呼ぶ。
こうした問題は、物理ベースのコードの高精度な近似であるサロゲートモデルの使用によって緩和されることが多い。サロゲートモデルは方程式の形をとるため、非常に高速に評価できる。これによって、大規模な多変量解析を可能になる。例えば、設計空間全体にわたるモンテカルロシミュレーションは物理ベースのコードでは困難であるが、応答曲面方程式の形をとることが多いサロゲートモデルを用いることで、こうした高度な解析も容易に行うことが可能である。
目的
多変量解析を適用し、複雑に絡み合う変数間の関係性を整理・抽出することで、主に以下の目的で活用する。
- 多変量仮説検定
- 次元削減 - 変数の数を減らしデータを要約する。
- 潜在構造の発見[3]
- クラスタリング - 似たものをグループに分類する
- 多変量回帰分析[4] - 変数間の関係性を数式化する
- 分類および判別分析 - データがどのグループに属するか予測・分類する
- 変数選択
- 多次元分析 - 多次元尺度構成法などを用いた空間的把握
- データマイニング
基礎となる確率分布
多変量解析では、単変量解析における正規分布などのように、複数の変数を同時に扱うための拡張された確率分布が用いられる。多くの多変量解析モデルは、データがこれらの分布に従うことを前提(あるいは近似)として構築されている。代表的な多変量分布は以下の通りである
- 多変量正規分布 - 多変量解析において最も中心的な役割を果たす分布。単変量の正規分布を多次元に拡張したものであり、主成分分析や線形判別分析など、多くの古典的な手法がデータの多変量正規性を仮定している。
- ウィシャート分布 - 多変量正規分布に従う標本群から得られた「分散共分散行列」が従う確率分布。カイ二乗分布を多変量に拡張したものであり、多変量解析における分散の推定や検定に用いられる。
- 多変量t分布 - スチューデントのt分布を多次元に拡張した分布。外れ値に対して多変量正規分布よりも堅牢(ロバスト)であるため、実データ解析において有用である。
- 逆ウィシャート分布 - ウィシャート分布の逆行列が従う分布。ベイズ統計学における多変量線形回帰などで、共分散行列の事前分布として用いられる重要な分布である。
不完全なデータの処理
実験的に取得されたデータセットにおいて、特定のデータポイントの一部のコンポーネントの値が欠損していることは非常に一般的である。データポイント全体を破棄するのではなく、欠損しているコンポーネントの値を「埋める」ことが一般的であり、このプロセスは「代入」と呼ばれる[5]。
分析の種類
MVAでは多くの異なるモデルが使用されており、それぞれ独自の分析タイプを持っている。
回帰・分散分析
- 重回帰分析/多変量回帰分析 - は、変数のベクトル内の要素が他の変数の変化に対して同時にどのように反応するかを記述できる式を決定しようと試みるものである。線形関係の場合、ここでの回帰分析は一般線形モデルの形式に基づいている。多変量回帰は多変数回帰とは異なると示唆する者もいるが、これについては議論があり、科学分野全体で常に当てはまるわけではない[6]。
- 多変量分散分析(MANOVA)/多変量共分散分析(MANCOVA) - 分散分析を拡張して、同時に分析される複数の従属変数があるケースをカバーするものである。
- 正準相関分析 - 2つの変数セット間の線形関係を見つける。これは2変量相関の一般化(すなわち正準化)されたバージョンである[7]。
- 同時方程式モデル - 異なる従属変数を持つ複数の回帰方程式を含み、それらを一緒に推定する。
- ベクトル自己回帰 - 様々な時系列変数のそれ自身およびお互いの遅行値に対する同時回帰を含む。
次元削減・潜在構造の分析
- 主成分分析(PCA) - 元のセットと同じ情報を含む新しい直交変数のセットを作成する。ばらつきの軸を回転させて、ばらつきの割合が減少する順序に要約されるように新しい直交軸のセットを与える。
- 因子分析 - PCAに似ているが、ユーザーが元のセットよりも少ない指定された数の合成変数を抽出できるようにし、残りの説明できないばらつきを誤差として残す。抽出された変数は潜在変数または因子として知られており、それぞれが観測された変数のグループにおける共変動を説明すると想定される。
- 独立成分分析 - 多変量データから、互いに独立な成分を分離・抽出する手法。
- コレスポンデンス分析(CA)/相互平均法 - PCAのように、元のセットを要約する合成変数のセットを見つける。基礎となるモデルは、レコード(ケース)間にカイ二乗の非類似性があると仮定している。
- 冗長性分析(RDA) - 正準相関分析に似ているが、ある(独立)変数のセットから指定された数の合成変数を導き出し、別の(独立)セットにおける分散を可能な限り説明できるようにするものである[8]。これは回帰の多変量版にあたる[9]。
- 正準コレスポンデンス分析(制約付きコレスポンデンス分析、CCA) - 冗長性分析のように、2つの変数セットにおける同時変動を要約するためのものである。コレスポンデンス分析と多変量回帰分析の組み合わせである。基礎となるモデルは、レコード間にカイ二乗の非類似性があると仮定している。
- 数量化理論 (I類、II類、III類、IV類) - 質的データを量的に扱うための日本独自の多変量解析手法群。
分類・判別・グループ化
- 多次元尺度構成法は、レコード間のペアごとの距離を最もよく表す合成変数のセットを決定するための様々なアルゴリズムで構成される。元の方法は主座標分析(PCoA、PCAに基づく)である。
- 判別分析/正準変量分析 - 変数セットを使用して2つ以上のケースグループを区別できるかどうかを確立しようと試みるものである。
- 線形判別分析(LDA)は、正規分布する2つのデータセットから線形予測子を計算し、新しい観測値の分類を可能にする。
- クラスター分析(クラスタリングシステム) - 同じクラスターのオブジェクト(ケース)が、異なるクラスターのオブジェクトよりも互いに類似するように、オブジェクトをグループ(クラスターと呼ばれる)に割り当てる。
- 再帰的分割 - 二値の従属変数に基づいて母集団のメンバーを正しく分類しようと試みる決定木を作成する。
マッピング・知覚空間の把握
- 多次元尺度構成法 (MDS) - レコード間のペアごとの距離を最もよく表す合成変数のセットを決定するための様々なアルゴリズムで構成される。元の方法は主座標分析(PCoA、PCAに基づく)である。
- コンジョイント分析 - 製品やサービスの持つ複数の要素が、消費者の選択にどう影響するかを分析する手法。
その他
- 人工ニューラルネットワーク - 回帰法やクラスタリング法を非線形多変量モデルに拡張する。
- 主応答曲線分析(PRC) - PDAに基づく方法で、時間の経過に伴う対照処理の変化を補正することにより、ユーザーが時間の経過に伴う処理効果に焦点を当てることを可能にする[10]。
- 多変量データの統計グラフィックス - ツアー、平行座標プロット、散布図行列などの統計グラフィックスを使用して、多変量データを探索できる。
- 相関のイコノグラフィー - 相関行列を、「注目すべき」相関が実線(正の相関)または点線(負の相関)で表される図に置き換えることから成る。
歴史
C.R.ラオは、そのキャリアを通じて、特に20世紀半ばに多変量統計理論に多大な貢献をした。彼の主要な著作の1つは、1952年に出版された「Advanced Statistical Methods in Biometric Research(生物測定学研究における高度な統計手法)」というタイトルの本である。この著作は、多変量統計における多くの概念の基礎を築いた[11]。 アンダーソンの1958年の教科書『An Introduction to Multivariate Statistical Analysis』[12]は、一世代の理論家や応用統計学者を教育した。アンダーソンの本は、尤度比検定を通じた仮説検定と、許容性、不偏性、単調性といった検出力関数の特性を強調している[13][14]。
MVAはかつて、基盤となるデータセットのサイズと複雑さ、およびその高い計算コストのために、統計理論の文脈でのみ議論されていた。計算能力の劇的な向上に伴い、現在MVAはデータ分析においてますます重要な役割を果たしており、オーミクス分野などで広く応用されている。
ソフトウェアとツール
多変量解析のためのソフトウェアパッケージやその他のツールは無数に存在し、以下のようなものがある。
- JMP
- MiniTab
- Calc
- PSPP
- R[15]
- SAS
- Python向けのSciPy
- SPSS
- Stata
- STATISTICA
- The Unscrambler
- WarpPLS
- SmartPLS
- MATLAB
- Eviews
- NCSS(多変量解析を含む)
- The Unscrambler® X(多変量解析ツール)
- SIMCA
- DataPandit
各分野での利用
人文地理学
人文地理学では、地域分析において多変量解析が重要な手法となる[16]。1950年代後半以降、計量地理学の理論を構築していくうえで多変量解析が利用されていった[17]。人文地理学では、重回帰分析による地域間の連結性の把握、主成分分析による都市の内部構造の分析、因子分析・クラスター分析による因子生態分析や等質地域・機能地域の地域区分などが行われる[18]。
地域分析で多変量解析を行う場合は、まず地理行列を作成する[19]。等質地域の設定を行う場合は属性行列、機能地域の設定を行う場合は相互作用行列を作成し、多変量解析を行うことになる[20]。
脚注
- ^ 水野 1996, p. 1.
- ^ Olkin, I. (2001). Smelser, Neil J.. ed (英語). Multivariate Analysis: Overview. Pergamon. pp. 10240–10247. ISBN 978-0-08-043076-8 2026年3月31日閲覧。
- ^ Huang, Biwei; Low, Charles Jia Han; Xie, Feng; Glymour, Clark; Zhang, Kun (2022). “Latent Hierarchical Causal Structure Discovery with Rank Constraints”. arXiv 2026年3月31日閲覧。.
- ^ “Multivariate Regression Analysis | Stata Data Analysis Examples”. stats.oarc.ucla.edu. 2026年3月31日閲覧。
- ^ J.L. Schafer (1997) (英語). Analysis of Incomplete Multivariate Data. Chapman & Hall/CRC. ISBN 978-1-4398-2186-2
- ^ Hidalgo, B; Goodman, M (2013). “Multivariate or multivariable regression?”. Am J Public Health 103 (1): 39-40. doi:10.2105/AJPH.2012.300897. PMC 3518362. PMID 23153131 2026年3月31日閲覧。.
- ^ 2変量ガウス問題の洗練されていないアナリストは、確率を正確に測定するための粗雑だが正確な方法(N個の残差の二乗の合計Sを求め、最小値Smを引いた上でその差をSmで割り、結果に(N - 2)を掛けて、その積の半分の逆対数を取る)を役立てるかもしれない。
- ^ “Chapter 6 Redundancy analysis | Workshop 10: Advanced Multivariate Analyses in R”. Developed and maintained by the contributors of the QCBS R. Workshop. 2026年3月31日閲覧。
- ^ Van Den Wollenberg, Arnold L. (1977). “Redundancy analysis an alternative for canonical correlation analysis”. Psychometrika 42 (2): 207-219. doi:10.1007/BF02294050.
- ^ ter Braak, Cajo J.F.; Šmilauer, Petr (2012) (英語). Canoco reference manual and user's guide: software for ordination (version 5.0). Ithaca, NY: Microcomputer Power. p. 292
- ^ Dasgupta, Anirban (2024). “C.R. Rao: Paramount statistical scientist (1920 to 2023)”. Proceedings of the National Academy of Sciences 121 (9): e2321318121. doi:10.1073/pnas.2321318121. PMC 10907269. PMID 38377193 2026年3月31日閲覧。.
- ^ T.W. Anderson (1958) (英語). An Introduction to Multivariate Analysis. New York: Wiley. ISBN 0471026409
- ^ Sen, Pranab Kumar (1986). “Review: Contemporary Textbooks on Multivariate Statistical Analysis: A Panoramic Appraisal and Critique”. Journal of the American Statistical Association 81 (394): 560-564. doi:10.2307/2289251. ISSN 0162-1459.
- ^ Schervish, Mark J. (1987). “A Review of Multivariate Analysis”. Statistical Science 2 (4): 396-413. doi:10.1214/ss/1177013111. ISSN 0883-4237.
- ^ CRANには多変量データ分析に利用できるパッケージの詳細がある。[1]
- ^ 村山・駒木 2013, p. 19.
- ^ 村山・駒木 2013, p. 21.
- ^ 村山・駒木 2013, pp. 22–23.
- ^ 村山・駒木 2013, p. 22.
- ^ 村山・駒木 2013, p. 25.
参考文献
- 水野欽司『多変量データ解析講義』朝倉書店、1996年。 ISBN 4-254-12548-8。
- 村山祐司、駒木伸比古『新版 地域分析』古今書院、2013年。 ISBN 978-4-7722-5272-0。
教科書
- 小西貞則:「多変量解析入門:線形から非線形へ」、岩波書店、ISBN 978-4-00-005653-3 (2010年1月26日).
外部リンク
- 『多変量解析』 - コトバンク
- 多変量解析とは?入門者にも理解しやすい手順や具体…|Udemy メディア
|
|
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 標本調査 | |||||||||||||||
| 記述統計学 |
|
||||||||||||||
| 推計統計学 |
|
||||||||||||||
| ベイズ統計学 |
|
||||||||||||||
| 相関 |
|
||||||||||||||
| モデル | |||||||||||||||
| 回帰 |
|
||||||||||||||
| 分類 |
|
||||||||||||||
| 教師なし学習 |
|
||||||||||||||
| 統計図表 | |||||||||||||||
| 生存時間分析 | |||||||||||||||
| 歴史 |
|
||||||||||||||
| 応用 | |||||||||||||||
| 出版物 |
|
||||||||||||||
| 全般 | |||||||||||||||
| その他 | |||||||||||||||
| |
|||||||||||||||
| 典拠管理データベース: 国立図書館 |
|---|
 |
この項目は、社会科学に関連した書きかけの項目です。この項目を加筆・訂正などしてくださる協力者を求めています(PJ:社会科学)。 |
 |
この項目は、自然科学に関連した書きかけの項目です。この項目を加筆・訂正などしてくださる協力者を求めています(Portal:自然科学)。 |
多変量解析
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2022/03/14 05:27 UTC 版)
多変量グレンジャー因果性検定は通常、ベクトル自己回帰モデル(VAR)を時系列データに当てはめて行われる。特に、時間 t = 1 , … , T {\displaystyle t=1,\ldots ,T} において X ( t ) ∈ R d × 1 {\displaystyle X(t)\in \mathbb {R} ^{d\times 1}} を d {\displaystyle d} 次元の多変量時系列とする。グレンジャー因果性は、 L {\displaystyle L} 個の時点に対するVARモデルで以下のように行われる。 X ( t ) = ∑ τ = 1 L A τ X ( t − τ ) + ε ( t ) , {\displaystyle X(t)=\sum _{\tau =1}^{L}A_{\tau }X(t-\tau )+\varepsilon (t),} ここで、 ε ( t ) {\displaystyle \varepsilon (t)} はホワイトガウスランダムベクトルであり、 A τ {\displaystyle A_{\tau }} はそれぞれの τ {\displaystyle \tau } における行列である。 τ = 1 , … , L {\displaystyle \tau =1,\ldots ,L} において要素 A τ ( j , i ) {\displaystyle A_{\tau }(j,i)} の1つ以上がゼロよりも(絶対値が)大幅に大きい場合には、時系列 X i {\displaystyle X_{i}} から別の時系列 X j {\displaystyle X_{j}} へグレンジャー因果性があるとされる。
※この「多変量解析」の解説は、「グレンジャー因果性」の解説の一部です。
「多変量解析」を含む「グレンジャー因果性」の記事については、「グレンジャー因果性」の概要を参照ください。
多変量解析と同じ種類の言葉
固有名詞の分類
- 多変量解析のページへのリンク
