乱塊法
例題:
「表 1 のようなデータがある。4 種の肥料間で収量に差があるか,また,3 種の品種ごとに差があるか検定しなさい。」
| 肥料 | ||||
|---|---|---|---|---|
| 品種 | B1 | B2 | B3 | B4 |
| A1 | 9 | 17 | 12 | 16 |
| A2 | 1 | 21 | 16 | 11 |
| A3 | 7 | 19 | 6 | 9 |
R による解析
> randblk(dat) # この関数の定義を見る SS d.f. MS F value P value Treatment 268.66667 3 89.55556 5.4923339 0.03719245 Replication 21.50000 2 10.75000 0.6592845 0.55102999 Residual 97.83333 6 16.30556 NA NA Total 388.00000 11 35.27273 NA NA aov 関数を用いる場合 > m <- matrix(c(9,1,7,17,21,19,12,16,6,16,11,9),3,4) > m [,1] [,2] [,3] [,4] [1,] 9 17 12 16 [2,] 1 21 16 11 [3,] 7 19 6 9 > df <- data.frame(x=as.vector(m), Treatment=as.factor(col(m)), Replication=as.factor(row(m))) > df x Treatment Replication 1 9 1 1 2 1 1 2 3 7 1 3 4 17 2 1 5 21 2 2 6 19 2 3 7 12 3 1 8 16 3 2 9 6 3 3 10 16 4 1 11 11 4 2 12 9 4 3 > summary(aov(x ~ Treatment + Replication, df)) Df Sum Sq Mean Sq F value Pr(>F) Treatment 3 268.667 89.556 5.4923 0.03719 * Replication 2 21.500 10.750 0.6593 0.55103 Residuals 6 97.833 16.306 --- Signif. codes: 0 `***' 0.001 `**' 0.01 `*' 0.05 `.' 0.1 ` ' 1
乱塊法
例題:
「8 名のボランティアを被検者として,ある薬剤を投与しない場合(0mg),10,20,40,80mg 投与する場合の 5 通りの処置を行い,効果を測定した結果は表 5 のようになった。薬剤の効果があるかどうかを 5% の有意水準で検定しなさい。」
| 投与量 | |||||
|---|---|---|---|---|---|
| 被検者 | 0mg | 10mg | 20mg | 40mg | 80mg |
| 1 | 5 | 60 | 35 | 62 | 76 |
| 2 | 24 | 44 | 74 | 63 | 76 |
| 3 | 56 | 57 | 70 | 74 | 79 |
| 4 | 44 | 51 | 55 | 23 | 84 |
| 5 | 8 | 68 | 50 | 24 | 64 |
| 6 | 32 | 66 | 45 | 63 | 46 |
| 7 | 25 | 38 | 70 | 58 | 77 |
| 8 | 48 | 24 | 40 | 80 | 72 |
R による解析
> randblk(dat) # この関数の定義を見る SS d.f. MS F value P value Treatment 7076.75 4 1769.1875 6.2886477 0.000965823 Replication 1771.50 7 253.0714 0.8995525 0.520523332 Residual 7877.25 28 281.3304 NA NA Total 16725.50 39 428.8590 NA NA
乱塊法
乱塊法は,対応のあるデータにおける平均値の差の検定である。
乱塊法は農事研究における圃場試験での伝統的な呼び方であり,表 1 のようなデータを対象としている。
例題:
「表 1 のようなデータがある。4 種の肥料間で収量に差があるか,また,3 種の品種ごとに差があるか検定しなさい。」
| 肥料 | ||||
|---|---|---|---|---|
| 品種 | B1 | B2 | B3 | B4 |
| A1 | 9 | 17 | 12 | 16 |
| A2 | 1 | 21 | 16 | 11 |
| A3 | 7 | 19 | 6 | 9 |
検定手順:
- 前提
- r 人の各被験者に c 種の処理を行い,測定値 Xij(i = 1,2,... ,r;j=1,2,... ,c)を得たとする。この場合の被験者(一般的には c 種類の処理が施される単位)をブロックと呼ぶ。
表 2.乱塊法の記号表現 被験者 処理1 処理2 … 処理c 1 X11 X12 … X1c 2 X21 X22 … X2c : : : : : r Xr1 Xr2 … Xrc
- 全体の平均を μ,処理 j の平均を μ・j,個体 i の平均を μi・,誤差を εij とすると次式のように表せる。
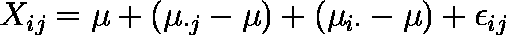
または,
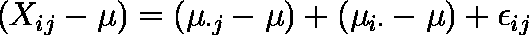
- μ,μ・j ,μi・ に標本値
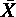 ・・ ,・j ,i・ をあてると,次式になる。
・・ ,・j ,i・ をあてると,次式になる。
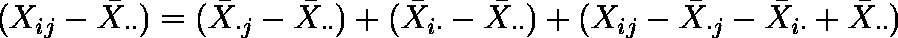
- 式の両辺を 2 乗して i,j について和を求めると,次式が得られる。
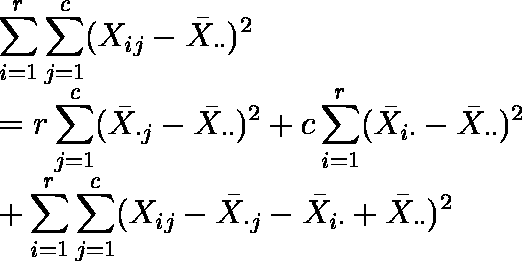
この式は,測定値の全変動 SSt が,処理の差 SSt と個体の差 SSr および残差 SSe に分解されることを表している。
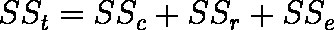
- 乱塊法の解析結果を表 3 のような分散分析表で表す。
MSc ,MSr ,MSe ,MSt は,対応する平方和を自由度で割ったもの表 4.乱塊法の分散分析表 変動要因 平方和 自由度 平均平方 F 値 処理の差 SSc c - 1 MSc MSc / MSe 個体の差 SSr r - 1 MSr MSr / MSe 残差(誤差) SSe ( c - 1) ( r - 1 ) MSe 全体 SSt c r - 1 MSt
表 5.表 1 のデータの乱塊法による分散分析 肥料 品種 B1 B2 B3 B4 平均値 A1 9 17 12 16 13.500 A2 1 21 16 11 12.250 A3 7 19 6 9 10.250 平均値 5.667 19.000 11.333 12.000 12.000
偏差平方 9.000 25.000 0.000 16.000 2.250 121.000 81.000 16.000 1.000 0.063 25.000 49.000 36.000 9.000 3.063 40.111 49.000 0.444 0.000
分散分析表 要因 平方和 自由度 平均平方 F 値 有意確率 肥料の差 268.667 3 89.556 5.492 0.037 品種の差 21.500 2 10.750 0.659 0.551 残差 97.833 6 16.306 全体 388.000 11 35.273
- 処理間の有意差の検定は,MSc / MSe が,第 1 自由度 c - 1,第 2 自由度 が ( c - 1 ) ( r - 1 ) の F 分布に従うことを利用する。
例題では,肥料の差についての検定統計量は F0 = 5.492 で,自由度(3,6)の F 分布に従う。
- 個体間の有意差の検定は,MSr / MSe が,第 1 自由度 r - 1,第 2 自由度 が ( c - 1 ) ( r - 1 ) の F 分布に従うことを利用する。
例題では,肥料の差についての検定統計量は F0 = 0.659 で,自由度(2,6)の F 分布に従う。
- それぞれの自由度を持つ F 分布において,有意確率を P = Pr{F ≧ F0} とする。
F 分布表(α = 0.05,α = 0.025,α = 0.01,α = 0.005),または F 分布の上側確率の計算を参照すること。
例題では,肥料の差については,自由度が(3,6)の F 分布において,Pr{F ≧ 4.76}= 0.05 であるから,P = Pr{F ≧ 5.492}< 0.05 である(正確な有意確率:P = 0.037)。
品種の差については,自由度が(2,6)の F 分布において,Pr{F ≧ 5.14}= 0.05 であるから,P = Pr{F ≧ 0.659}> 0.05 である(正確な有意確率:P = 0.551)。
- 帰無仮説の採否を決める。
例題では,有意水準 5% で検定を行うとすれば(α = 0.05),肥料の差においては P < α であるから,帰無仮説を棄却する。すなわち,「肥料の差はある」とする。品種の差においては P > α であるから,帰無仮説を採択する。すなわち,「品種の差はない」とする。
乱塊法
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2024/10/27 01:03 UTC 版)

|
この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。 (2024年10月)
|
乱塊法とはフィッシャーの3原則である無作為化、反復、局所管理のすべてを取り入れた実験デザインである。
検定精度
完全無作為化法と比較すると、乱塊法は誤差分散が小さくなるため検定精度が高くなる。しかし、乱塊法は誤差の自由度が低くなるため、一般的に誤差の自由度を10以上確保できる場面で乱塊法を選択する方が有利になると考えられる。
外部リンク
|
|
|||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 標本調査 | |||||||||||||||
| 記述統計学 |
|
||||||||||||||
| 推計統計学 |
|
||||||||||||||
| ベイズ統計学 |
|
||||||||||||||
| 相関 |
|
||||||||||||||
| モデル | |||||||||||||||
| 回帰 |
|
||||||||||||||
| 分類 |
|
||||||||||||||
| 教師なし学習 |
|
||||||||||||||
| 統計図表 | |||||||||||||||
| 生存時間分析 | |||||||||||||||
| 歴史 |
|
||||||||||||||
| 応用 | |||||||||||||||
| 出版物 |
|
||||||||||||||
| 全般 | |||||||||||||||
| その他 | |||||||||||||||
| |
|||||||||||||||

- 乱塊法のページへのリンク
