データマイニング
データ・マイニング data mining
データマイニング
データマイニングとは、データベースに蓄積されている大量のデータから、統計や決定木などを駆使して、マーケティングに必要な傾向やパターンなどの隠された規則性、関係性、仮説を導き出す手法のことである。マイニング(mining)とは「採鉱」を意味するもので、いわば眠っている金脈を探り当てることになぞらえられている。
一見無秩序・無関係に見えるデータの山も、着眼点次第では各事項の間に有益な連関が見えてくることが少なくない。例えば、ある商店ではサングラスを買う人の多くが一緒にガムを買っているという事実が見つかるかも知れない。あるいは他の店舗では、曇りがちの日には生魚の売り上げが伸びているかもしれない。こうした連関を実績として見出すことによって、サングラスの陳列棚の近くにガムを配置する、とか、雲の多い日に鮮魚のセールを実施するとか、効果的なマーケティングを行うことができる。
データマイニングは、データベースの発展を中心とした情報技術の向上によって盛んに行われるようになった手法であるといえる。元となるデータが多ければ多いほど、処理作業は膨大なものになるが、実証性は高くなる。既存データを専用のデータベースに取り込んで意思決定に活用するシステムはデータウェアハウスと呼ばれるが、データウェアハウスは一個のデータマイニングツールであるといえる。
| マーケティング: | ソーシャルコマース ステップメール ステルスマーケティング データマイニング 電子クーポン ティーザーサイト データベースマーケティング |
データマイニング
【英】:data mining
概要
データベースに蓄えられた多量のデータから, 機械学習(machine learning)や統計的手法(statistical method)を用いて データの中に含まれる知識を発掘する手法をいう. 知識発見プロセスとしての, データ獲得,選択,前処理,変換,知識発見アルゴリズムの適用,解釈,評価といった 一連のサイクルを指す. 獲得した知識に基づく意思決定が目的であり, データ収集,発掘,評価といった人間と計算機の共同作業を伴う知識マネジメントとして捉えられる.
詳説
データマイニング (data mining)は, データベース (data base) [5] に蓄えられた大量の生データに対して, 機械学習 (machine learning)に関連する複数の手順を用いる戦略により, データに内在する規則性 (regularity), 制約 (constraint), ルール (rule)などを効率よく求める研究である. なお, データベースからの知識発見 (KDD: knowledge discovery in databases)とも呼ばれ, 知識発見 (knowledge discovery)に関わる多数の学習アルゴリズムが, 人工知能だけでなくデータベースや統計学の側面を含めて研究されている. まず, ノイズや例外を含み疎な構造をもつことも多い生データを対象としたデー タマイニングに共通する知識発見の手順を(1)~(6)に簡単に示す [1].
【手順】
(1)対象となるデータに対する既知の性質(背景知識)を利用してデータ収集を行い, データベースやデータウェアハウス (data warehouse)に格納する. (2)データに対する選択操作を前処理として行う. この段階はデータクリーニングと呼ばれる. (3)実装を前提とする制約のもとでデータの次元低減などによる変形操作を行う. (4)データマイニングを行うアルゴリズムを実行する. (5)導出された記述の解釈, ならびに, 記述の妥当性の検証を後処理として行う. (6)最終的な記述が評価され, 知識となる.
手順(4)のアルゴリズムで求まる知識の表現法によって, データの統計的解析 (statistical analysis of data)とデータの論理的解析 (logical analysis of data)の二種類に大きく分類される.
データの論理的解析の一種である決定木 (decision tree)を図1に示す. なお, 決定木を求めるアルゴリズムとしてID3 [4] などが知られており, エントロピーやMDL(minimum description length)基準が記述を選択する際に用いられる.
|
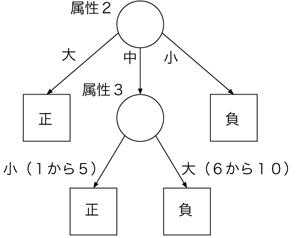 | |||||||||||||||||||||||||||||||||||||||||||||
図1: 決定木を用いた概念学習の一例 | ||||||||||||||||||||||||||||||||||||||||||||||
関係データベースの問合せ言語SQLのGroupBy操作の拡張として位置付けられる結合ルール (association rule)を求めるアルゴリズムの研究も数多い. 結合ルールを求めるために, 最小サポート(support)値と最小確信度(confidence)を定めるヒューリスティックな閾値が用いられる. なお, 最小閾値により多数のルール導出を制限するだけではなく, 新規性や興味深さの弱いルールを最大閾値で抑制することもある. また, 頻度の高い購買パターンを結合ルールが表すため, データベースマーケティング(database marketing)などをターゲットに, 計算機アーキテクチャを含めた効率良い実装が進んでいる.
その他, 多変量解析の手法を用いるクラスター分析 (cluster analysis)や, 因果関係を表現するベイズネットワーク (Baysian network)や, 論理的表現に対する帰納推論プログラミング(ILP: inductive logicprogramminge)などもアプローチの一つである. また, ルールの理解可能性を高める上で, ルールの視覚化 (visualization)も欠かせない.
なお, ラフ集合(rough sets), ファジー理論(fuzzy theory), ニューラルネットワーク(neural network), 遺伝アルゴリズム(genetic algorithm)などの研究とも密接に関係している.
ところで, データマイニングの対象となるデータは, 航空会社, 銀行, クレジットカード会社, 電話, 保険などでのトランザクションだけではなく, WWWデータや医療データなどの異なる性質をもつデータも含まれる [2]. 特に, 学習データの種類が限定される場合, 地理データに対しては空間データマイニング(spatial data mining), 文書データに対してはテキストマイニング(text mining)などと呼ぶ. また, データマイニングに関連したシフトウェア(siftware)と呼ばれるソフトウェアの開発も盛んである.
なお, 良質な知識を発見するには, 複数のアルゴリズムを適用するだけではなく, データの前処理・ルールの後処理が重要となる. したがって, 実用化に向けて, 例えば, 各種情報システムを効果的に運用することを考えたデータ収集戦略を決定しなければならない.
[1] U. M. Fayyad, G. Piatetsky-Shapiro, P. Smyth and R. Uthurusamy, Advances in Knowledge Discovery and Data Mining, AAAI/MIT Press, 1996.
[2] R. Michalski, I. Bratko and M. Kubat, Machine Learning and Data Mining, Methods and Applications, John Wiley & Sons Ltd., 1998.
[3] J. Pearl, Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference, Morgan-Kaufmann, 1988.
[4] J. R. Quinlan, C4.5: Programs for Machine Learning, Morgan Kaufmann Publishers, Inc., 1993. 古川康一監訳, 『AIによるデータ解析』, トッパン, 1995.
[5] J. D. Ullman, Principles of Database and Knowledge-Base Systems, Vol.I, Vol.II, Computer Science Press, 1988.
| システム分析・意思決定支援・特許: | データウェアハウス データベース データベース管理 データマイニング トレードオフ分析 ハードシステム思考 ブレーンストーミング |
| 近似・知能・感覚的手法: | ソフトコンピューティング タブー探索 デンプスター・シェファーの証拠理論 データマイニング ナップサック問題 ニューラルネットワーク ニューラルネットワークによる学習 |
- dataminingのページへのリンク
