近似アルゴリズム
【英】:approximate algorithm
概要
厳密解を求めることが保証される厳密解法 (exact algorithm) に対して,近似解を求めるアルゴリズムのこと.NP困難問題に対する多項式時間アルゴリズムなど,実用的な計算時間を実現するために厳密性を犠牲にすることが多い.発見的手法 (heuristic algorithm) とも呼ばれる.
詳説
組合せ最適化問題の中には, 最適解を求めることが現実的に困難な問題が数多く存在する. どのようなアルゴリズムを用いても莫大な計算時間, 計算量が必要になるような問題で, 計算機の性能に依存するというような次元の話ではなく, 問題の構造そのものに依存するという意味である. NP完全, NP困難なクラスに属する問題はそのような問題の代表例である. ナップサック問題 (knapsack problem), 最大カット問題 (maximum cut problem), 集合カバー問題 (set covering problem)等の整数計画問題の多くはこれらのクラスに分類される. これらの問題を解くアルゴリズムには, その計算時間が問題の規模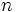 の多項式として表されるものが一般的には存在しないと考えられている. しかし, 問題中のパラメータを含めると多項式時間で最適解を求めることができる場合もあり, そのようなアルゴリズムを弱多項式時間アルゴリズムと呼び, 動的計画法, 分枝限定法等の手法が用いられる.
の多項式として表されるものが一般的には存在しないと考えられている. しかし, 問題中のパラメータを含めると多項式時間で最適解を求めることができる場合もあり, そのようなアルゴリズムを弱多項式時間アルゴリズムと呼び, 動的計画法, 分枝限定法等の手法が用いられる.
NP完全, NP困難な問題で弱多項式時間アルゴリズムも存在しないもの, あるいは問題規模の大きいものについて, 対処法がないわけではない. 問題を解く際, 常に厳密な最適解が必要かどうかというと, そうとは限らない場合も多々ある. つまり, 時間と労力, 更には経済的負担を強いて厳密解を求めるよりも, 厳密な最適解ではないけれども実際的な応用に差し支えない程度の近似解を比較的速い時間で簡単に求める方が現実的であると考えられる. このような近似解を求めるアルゴリズムを近似アルゴリズム (approximation algorithm)と呼ぶ. 欲張り法(greedy method)に代表されるように, それらのアルゴリズムが発見的探索法に基づいていることから, ヒューリスティックアルゴリズムとも呼ばれる. 近似アルゴリズムは得られる近似解の精度, つまり近似解に対応する評価関数の値と厳密解に対応するそれとの差の比率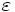 に従って, ε-近似アルゴリズム (
に従って, ε-近似アルゴリズム (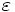 -approximation algorithm)という性能表現がなされ, 最近ではPTAS (polynomial time approximation scheme)のような新たな枠組みによる近似アルゴリズムの性能評価, 研究が行われている.
-approximation algorithm)という性能表現がなされ, 最近ではPTAS (polynomial time approximation scheme)のような新たな枠組みによる近似アルゴリズムの性能評価, 研究が行われている.
近似解法に関する研究は盛んに行われ, より精度の高い近似解を, より速く求めるために, 最近ではメタヒューリスティックスあるいはモダンヒューリスティックスと呼ばれる枠組が注目を集めている. この中の主なものとしてアニーリング法, タブー探索法, 遺伝的アルゴリズム等が挙げられるが, 基本的にこれらの手法は近似解を局所探索法 (local search)に基づき改善してゆくというものであり, 解の近傍生成法, 探索則, 解の更新則が性能評価のポイントとなる. つまり, 人間の発見的知識をどのような形でアルゴリズムに反映させるかということが非常に重要であり, 「メタ」と呼ばれる所以である.
[1] C. R. Reeves, Modern Heuristic Techniques for Combinatorial Problems, Blackwell Scientific Publications, 1993. 横山隆一, 奈良宏一, 佐藤晴夫, 鈴木昭男, 荻本和彦, 陳洛南 訳,『モダンヒューリスティックス』, 日刊工業新聞社, 1997.
[2] R. Sedgewick, Algorithms, 2nd ed., Addison Wesley, 1988. 野下浩平, 星守, 佐藤創, 田口東 訳,『アルゴリズム 第3巻』, 近代科学社, 1992.
[3] W. J. Cook, W. H. Cunningham, W. R. Pulleyblank and A. Schrijver, Combinatorial Optimization, John Wiley & Sons, 1998.
[4] T. C. Hu, Combinatorial Algorithms, Addison Wesley, 1982.
[5] A. V. Aho, J. E. Hopcroft and J. D. Ullman, Data Structures and Algorithms, Addison Wesley, 1983.
近似アルゴリズム (スケジューリングの)
近似アルゴリズム
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2025/02/25 13:22 UTC 版)
近似アルゴリズム(きんじアルゴリズム、英: approximation algorithm)とは、組合せ最適化問題の近似解を得るためのアルゴリズムを言う[1][2][3][4]。近似解とは、実行可能解(かつ問題の何らかの制約を満たす解)ではあるが、正解(厳密解)ではないものを言う。これは組合せ最適化問題の正解(すなわち最適解)であることが(厳密には)保証されないところの解を得るものである。なお、問題を変形した近似問題に対する正解を得るアルゴリズムも、元の問題に対する近似アルゴリズムと言える。
概要
近似アルゴリズムの中でも、そのアルゴリズムの出力する解の目的関数値と最適解の目的関数値の比(近似度)がある範囲内に収まることが保証されているもののことを特に、精度保証付き近似アルゴリズムと呼ぶ。そのような保証のないアルゴリズムは発見的手法(ヒューリスティクス)と呼ばれる。前者と後者を区別し、前者のみを近似アルゴリズムと呼ぶ場合もある。
近似アルゴリズムは、主に多項式時間で厳密に解くことが難しいNP困難問題に対して考えられるが、多項式時間で計算可能な問題に対しても、より早い計算時間で解を求めるという目的で用いられることもある。アルゴリズム理論の分野においては近年の中心的話題のひとつで、さまざまな問題に対する近似アルゴリズムが考案されている。また、可能な近似度の下界値を示す近似不可能性に関する結果も多く得られており、PCP定理などが有名。
例えば、最小頂点被覆問題には近似度2の単純なアルゴリズムが存在するが、近似度が定数の多項式時間アルゴリズムがないと考えられている問題もある。
脚注
- ^ David P. Williamson; David B. Shmoys (2011). The Design of Approximation Algorithms. ISBN 978-0521195270
- ^ V.V.ヴァジラーニ:「近似アルゴリズム」、丸善出版 (2012年7月17日)
- ^ J. ホロムコヴィッチ:「計算困難問題に対するアルゴリズム理論: 組合せ最適化・ランダマイゼ-ション・近似・ヒュ-リスティクス」、丸善出版 (2016年1月10日)
- ^ 浅野孝夫:「近似アルゴリズム: 離散最適化問題への効果的アプローチ」、共立出版、ISBN 978-4-320-12177-5 (2019年6月27日)
関連項目
|
|
||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 非線形(無制約) |
|

|
||||||||||||
| 非線形(制約付き) |
|
|||||||||||||
| 凸最適化 |
|
|||||||||||||
| 組合せ最適化 |
|
|||||||||||||
| メタヒューリスティクス | ||||||||||||||
 |
この項目は、コンピュータに関連した書きかけの項目です。この項目を加筆・訂正などしてくださる協力者を求めています(PJ:コンピュータ/P:コンピュータ)。 |

近似アルゴリズムと同じ種類の言葉
- 近似アルゴリズムのページへのリンク
