フォールト‐トレランス【fault-tolerance】
フォールトトレランス
フォールトトレランスとは、システムに障害が発生した場合にも正常に機能し続けることである。耐障害性などと和訳されることが多い。
通常のコンピュータは、システムの一部に支障を来たすと機能が停止してしまう。大規模なシステムやミッションクリティカルな業務のシステムには障害の発生は許されない。そのため、システムにある程度の冗長性を持たせることによって異常を回避する仕組みがとられる場合がある。例えば電源を多重化したり、ハードディスクを多重化したり(RAID)、無停電電源装置(UPS)を用いたりすることで、フォールトトレランスなシステムを実現することができる。
フォールトトレランスなシステムを構築する技術は、フォールトトレラント技術と呼ばれる。フォールトトレラント技術を用いたコンピュータはフォールトトレラントコンピュータと呼ばれる。フォールトトレラントコンピュータは耐障害コンピュータ、無停止コンピュータ、ノンストップコンピュータなどとも呼ばれる。サーバーの場合は特にフォールトトレラントサーバー(無停止型サーバー)などと呼ばれる場合もある。
フォールトトレラントと同様の概念には、フェイルセーフやフェイルソフトなどがある。フォールトトレランスは異常が生じても正常に機能することを意味するもので、フェイルセーフは人為的ミスによって他人に被害が及ばないようにする防止線のようなニュアンスがある。
フォールトトレランス
【英】:fault tolerance
概要
システムの一部に故障が発生しても, 全体としてはそれに耐える様な特性のこと, あるいは, その様な特性を実現するための設計・運用のアプローチのことをいう. フォールトトレランスの特性は, 故障が起こることは不可避であるという立場にたち, 冗長構成, 誤り検出, 誤りマスク, 再構成, 一貫性回復などの技術をあらかじめシステムに導入することで実現される. フォールトトレランスと対峙する概念にフォールトアボイダンスがある.
詳説
高信頼化システムを実現するための伝統的な手法のひとつは, システムを構成する個々の要素の信頼性を向上させることであり, これはフォールトアボイダンス (fault avoidance) とよばれる. 一方, いかに構成要素の信頼性が高くとも, 故障は本質的に避けられないものであるという前提に立ち, それらの要素またはシステムに, 故障に耐え得るような特性を持たせようとする手法が研究されてきた. この高信頼化手法がフォールトトレランス (fault tolerance) である. 本項では, フォールトトレランスの概念とその実現手法について述べる.
故障が発生しても, システムの機能に全く支障をきたさないことが, 理想的なフォールトトレランスの特性であるが, 機能の低下をシステムのある範囲だけに留める{フェイルソフト} (fail soft) や, 安全な状態で機能を停止するフェイルセーフ (fail safe) などの特性まで含めてフォールトトレランスという. この様な広い意味でのフォールトトレランスは, コンピュータシステムの普及とともに重要視されるようになり, 現在, フォールトトレランスは, 主としてコンピュータシステムの耐故障技術として認識されている.
ラプリエ (J. C. Laprie) は, フォールトアボイダンスとフォールトトトレランスを包括するディペンダビリティ (dependability) という統一的な概念を提案した [1, 2, 3]. それは, 「コンピュータシステムのディペンダビリティとは, 実行された仕事 (service) がどの程度正しく行われているかを明らかにするための品質 (quality) を示すものである」として定義された. 図1 に, ラプリエの提案した概念と用語の枠組を示す.
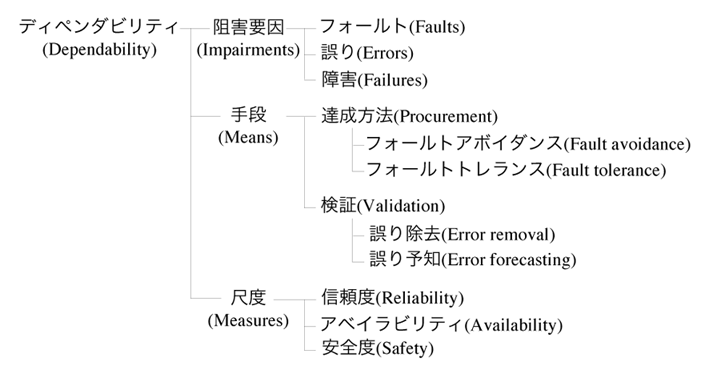 |
| 図1:ディペンダビリティの概念と用語の枠組 |
ディペンダビリティを阻害する要因として, フォールト (fault) , 誤り(errors), 障害 (failures) の3つが示されている. フォールト (または故障) とは, システムの機能損失や不具合などの原因をいい, 従来の故障の概念に, ソフトウェアのバグやオペレータの操作ミスまで含めた広い意味の用語として定義される. そして, フォールトが表面化してシステム内部に不具合が生じることを誤りという. また, その誤りが, システム外部のユーザ等に認識されたとき障害となるのである [1]. 階層的なシステムでは, これらの用語の関係は再帰的であることに注意したい. 例えば, あるサブシステムに発生した誤りは, そのサブシステムと外部との接点において障害として認識されるが, 同時にその障害は, サブシステムを含むシステム全体にとっての誤りをもたらすフォールトでもある. なお, これらの用語の定義は, フォールトトレランスの研究分野では広く認知されているが, 日本工業規格 JIS X 0014 (信頼性, 保守性及び可用性) 等の定義とは異なることを付け加えておく.
さて, フォールトトレランス技術とは, 誤りが障害として認識されるまえに, それを検出してマスク (または隠蔽) する技術 (masking), あるいは, マスクできない場合でもその影響をできるだけ狭い範囲に限定し, 速やかに正常状態へ回復させる技術であるといえる. この様な特性は, 基本的に何らかの冗長性 (redundancy) を導入することで得られる. 冗長化の対象となる計算機資源は, ハードウェア, ソフトウェア, 時間の 3 つに分類できる [2]. ハードウェアとソフトウェアの冗長化の多くは, 同一の構成要素を複数個用いることで実現され, 時間についての冗長化は, ひとつの要素を使って同じ処理を繰り返すことで実現される.
誤りを検出するためには, 例えば, 対象となるハードウェアを二重化冗長構成して結果を照合したり, 誤り検出のための冗長符号を用いたりする. そして, その誤りをマスクするために, TMR (triple modular redundancy) や  バージョンプログラミングなどの多数決冗長方式が用いられる. これらの冗長性は, 静的冗長 (static redundancy) と呼ばれる.
バージョンプログラミングなどの多数決冗長方式が用いられる. これらの冗長性は, 静的冗長 (static redundancy) と呼ばれる.
誤りのマスクに失敗して障害が発生すれば, システムの回復技術 (recovery techniques) が適用される. まず, 例えば待機冗長方式によって, 障害の認められたハードウェアを交換するなどの再構成が実行され, 続いてシステムの論理的一貫性を回復するために, ロールバック等のソフトウェア冗長が用いられる. これら障害回復のための冗長性は, 動的冗長 (dynamic redundancy) とよばれる.
[1] J. C. Laprie, "Dependable Computing and Fault Tolerance: Concepts and Terminology," Digest of Papers FTCS-15, (1985), 2-11.
[2] 当麻喜弘監修, 向殿政男編集, 『コンピュータシステムの高信頼化技術入門』, 日本規格協会, 1988.
[3] 向殿政男編集, 『フォールト・トレラント・コンピューティング』, 丸善, 1989.
[4] 南谷崇, 『フォールトトレラントコンピュータ』, オーム社, 1991.
| 信頼性・保全性: | フェイルセーフ フォールトアボイダンス フォールトデバッギング フォールトトレランス ベイズ信頼性 ベイズ信頼性実証試験 ベイズ推定 |
- fault toleranceのページへのリンク
