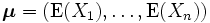 , (
, (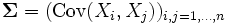 とすると,
とすると, 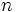
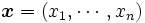 として
として
![f(\boldsymbol{x})=
\displaystyle{\frac{1}{(2\pi)^{n/2} \sqrt{|\mathbf{\Sigma}|}} \mathrm{exp}
\left[ - \frac{1}{2}
(\boldsymbol{x}-\boldsymbol{\mu}) \mathbf{\Sigma}^{-1}
(\boldsymbol{x}-\boldsymbol{\mu})^{\top} \right] }
\,](https://cdn.weblio.jp/e7/img/dict/orjtn/4587d779f18c0d90d03b5039f68dfb9d.png)
 は
は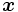 の
の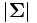 は
は辞書ショートカット
カテゴリ一覧
すべての辞書の索引
「multivariate normal distribution」の関連用語
| multivariate normal distributionのお隣キーワード |
multivariate normal distribution
検索ランキング
multivariate normal distributionのページの著作権
Weblio 辞書
情報提供元は
参加元一覧
にて確認できます。
| Copyright (C) 2026 (社)日本オペレーションズ・リサーチ学会 All rights reserved. | |
Tanaka Corpusのコンテンツは、特に明示されている場合を除いて、次のライセンスに従います: Creative Commons Attribution (CC-BY) 2.0 France. Creative Commons Attribution (CC-BY) 2.0 France. | |
| この対訳データはCreative Commons Attribution 3.0 Unportedでライセンスされています。 | |
 | Copyright © 1995-2026 Hamajima Shoten, Publishers. All rights reserved. |
|
|
Copyright © Benesse Holdings, Inc. All rights reserved. |
|
|
Copyright (c) 1995-2026 Kenkyusha Co., Ltd. All rights reserved. |
|
|
日本語ワードネット1.1版 (C) 情報通信研究機構, 2009-2010 License All rights reserved. WordNet 3.0 Copyright 2006 by Princeton University. All rights reserved. License |
|
|
Copyright (C) 1994- Nichigai Associates, Inc., All rights reserved. 「斎藤和英大辞典」斎藤秀三郎著、日外アソシエーツ辞書編集部編 |
|
|
This page uses the JMdict dictionary files. These files are the property of the Electronic Dictionary Research and Development Group, and are used in conformance with the Group's licence. |
ビジネス|業界用語|コンピュータ|電車|自動車・バイク|船|工学|建築・不動産|学問
文化|生活|ヘルスケア|趣味|スポーツ|生物|食品|人名|方言|辞書・百科事典
|
ご利用にあたって
|
便利な機能
|
お問合せ・ご要望
|
会社概要
|
ウェブリオのサービス
|
©2026 GRAS Group, Inc.RSS
