相関係数の統合(1)
各研究の,サンプルサイズ,相関係数がわかっているとき,これを統合して effect size r を得る方法は簡単といえば簡単。
4. が最もよく使われる。なお,スネデカー・コクランの本には,「複数の相関係数の同等性の検定」とそれに引き続いて,「統合した点推定値」が書いてありますね。それでは「サンプルサイズ − 3」の重み付けをするようになっています。
これを AWK スクリプトで書いてみると以下のようになる。
---------- begin # 相関係数の統合 effect size r BEGIN { k = sum_r = sum_z = Wsum_r = Wsum_z = 0 while (getline > 0) { n = $1 r = $2 z = fisher(r) printf "%10g %10g %10gn", n, r, z sum_r += r sum_z += z Wsum_r += r*n Wsum_z += z*n N += n k++ } print "単純平均 =", sum_r/k print "Fisher =", inv_fisher(sum_z/k) print "重みつき平均 =", Wsum_r/N print "重みつき Fisher =", inv_fisher(Wsum_z/N) } function fisher(r) { return 0.5*log((1+r)/(1-r)) } function inv_fisher(z) { return (exp(2*z)-1)/(exp(2*z)+1) } ---------- end
例題として用いたデータファイルは以下のように,標本サイズ,(変換された)相関係数の数値が記述されている。
---------- begin 131 0.51 129 0.48 111 0.60 119 0.46 155 0.30 121 0.21 112 0.22 145 0.25 ---------- end結果は以下の通り。3列目は Fisher の Z 変換値。
---------- begin 131 0.51 0.56273 129 0.48 0.522984 111 0.6 0.693147 119 0.46 0.497311 155 0.3 0.30952 121 0.21 0.213171 112 0.22 0.223656 145 0.25 0.255413 単純平均 = 0.37875 Fisher = 0.388253 重みつき平均 = 0.374262 重みつきFisher = 0.383253 ---------- end
なお,研究結果が相関係数で表されていないときは,それぞれの結果を相関係数に変換する公式がある。(これらは,容易に納得できるものもあるし,導出過程がわからないものもありますね ^_^; )
- 点双列相関係数 rpb
-
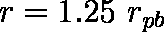
- 独立2群の平均値の差の検定における t 値
-
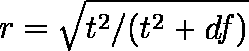
- 分割表のカイ二乗値
-
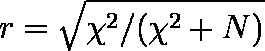
- 2×2 分割表のカイ二乗値
-
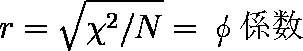
符号を付けること
- マン・ホイットニーの U 統計量
-
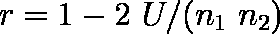
- effect size d
-
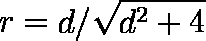
- 有意確率 P 値
- p ---> Z の後,

相関係数の統合(2)
- effect size r に関する meta-analysis の目的は
- sampling error について Schmidt-Hunter 法 (Hunter et al. 1982)
- sampling error variance s2e
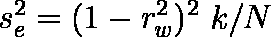
rw:各相関係数の重みつき平均
k: 研究の数
N: サンプルサイズの合計
- observed variance s2r
- population variance (residual variance) s2res
residual standard deviation sres
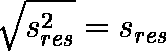
以上3つの量において,次式が成り立つ。
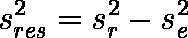
望ましいのは,s2res = 0 となること。あるいは,一様性の指標 s2r / s2e × 100% が 100% になること。
- sampling error variance s2e
- population effect size は,データが一様である場合にのみ信頼できる。
一様性については以下の基準を考える。
- Hunter らは,sampling variance が,少なくとも 75% 以上であればよいとした。
- 一様性の検定もある(スネデカー・コクランの本にあるものと同じようなものか?)
- population variance (residual variance) の値そのものの大きさ。(これが一番重要)
no06 の例では,observed variance s2r = 0.01985 sampling error variance s2e = 0.00548 population variance (residual variance) s2res = 0.1437
であり,s2e は,s2r の 28% に過ぎないことがわかる。 注:本文中の数値と後述の AWK スクリプトによる計算結果があわない!?どうも,ミスプリントのようだ。
s2r = 0.0199359 単純平均 = 0.37875 s2e = 0.00573744 % = 28.7794 Fisher = 0.388253 s2e = 0.00564021 % = 28.2917 重みつき平均 = 0.374262 s2e = 0.0057828 % = 29.0069 重みつき Fisher = 0.383253 s2e = 0.00569157 % = 28.5493
一様性の検定では,カイ二乗値 = 28, d.f. = 7 で,帰無仮説は棄却される。
注:スネデカー・コクランの本にあるものによると,これとはちょっと違うが同じような結果になる。
カイ二乗値 ・・・・・・・・・・・ 27.38226 自由度 ・・・・・・・・・・・・・・・ 7 P値 ・・・・・・・・・・・・・・・・・ 0.0002844 ** 母相関係数の推定値 ・・・ 0.3831321
以上の結果から一様性は疑わしいので,meta-analysis により系統的な変動要因について検討することになる。
- Hunter らは,sampling variance が,少なくとも 75% 以上であればよいとした。
- クラスター分析によって相関係数のクラスターを作るとよい。
どうも普通のクラスター分析と違うみたいだが,むりやり普通の方法を採用してみると(相関係数の値を目で見ただけでもわかるが),
平方距離(Ward 法) 0 0.0409 0.0818 0.123 0.164 0.204 0.245 0.286 +----+----+----+----+----+----+----+----+----+----+----+----+----+----+ 1 | |---| 2 | | | |-----------------------------------------------------------------| 4 | | | | | 3 ----| | | 5 -| | | | 6 ||--------------------------------------------------------------------| || 7 || | 8 |
のようになる。データ 1,2,3,4 と 5,6,7,8 の二つのクラスターがあると考えられる。
- 各クラスターのデータについて,今までと同じ分析を行う。
ここで示された数値が合わない(全体の分析と同じく)。Hunter et al. (1982)を見ないとダメか(^_^;)。どうも,本文のミスプリントみたいだ。
- また,各クラスターに共通する特性を検討することにより,moderator variable の存在についての知見が得られる。
参考文献
- Hunter, J. E., Schmidt, F. L., & Jackson, G. B. (1982).
Meta-analysis. Cummulating research findings across studies.
Beberly Hills, CA: Sage.
上の解析を AWK スクリプトで書くと次のようになる。
---------- begin # 相関係数の統合 effect size r -- 2 BEGIN { k = sum_r = sum_z = Wsum_r = Wsum_z = 0 while (getline > 0) { n = $1 r = $2 z = fisher(r) sum_r += r sum_z += z Wsum_r += r*n Wsum_z += z*n N += n k++ sr[k] = r } for (i = 1; i <= k; i++) { s2_r += (sr[i] - sum_r/k)^2 } s2_r /= k print "s2_r =", s2_r subroutine("単純平均", sum_r/k) subroutine("Fisher", inv_fisher(sum_z/k)) subroutine("重みつき平均", Wsum_r/N) subroutine("重みつき Fisher", inv_fisher(Wsum_z/N)) } function subroutine(str, r, x) { x = ((1-r^2)^2*k)/N print str, "=", r," s2_e =", x, " % =", x/s2_r*100 return x } function fisher(r) { return 0.5*log((1+r)/(1-r)) } function inv_fisher(z) { return (exp(2*z)-1)/(exp(2*z)+1) } ---------- end
- 相関係数の統合のページへのリンク
