ダミー変数を用いた重回帰分析による分析の例
まず最初に,分析に使用するデータを準備する。各アイテム変数を,「その変数が持つカテゴリー数 − 1」個のダミー変数に変換する(表 2 参照)。
例えば,あるアイテム変数が 3 個のカテゴリーを持つときは 2 個のダミー変数をあてる。アイテム変数の値が 1 のときは,2 個のダミー変数は 0, 0 とし,2 のときは 1, 0 とし,3 のときは 0, 1 とする。
|
|
***** 分析に用いた変数の基礎統計量 *****
| 平均値 | 不偏分散 | 標準偏差 | |
| y | 18.400000000 | 62.712857143 | 7.9191449755 |
| d11 | 0.400000000 | 0.257142857 | 0.5070925528 |
| d12 | 0.266666667 | 0.209523810 | 0.4577377082 |
| d21 | 0.333333333 | 0.238095238 | 0.4879500365 |
| d22 | 0.333333333 | 0.238095238 | 0.4879500365 |
***** 相関係数行列 *****
| y | 1.00000 | ||||
| d11 | -0.10494 | 1.00000 | |||
| d12 | 0.82761 | -0.49237 | 1.00000 | ||
| d21 | -0.21443 | -0.28868 | -0.10660 | 1.00000 | |
| d22 | 0.42146 | 0.00000 | 0.21320 | -0.50000 | 1.00000 |
| y | d11 | d12 | d21 | d22 | |
***** 重回帰式 *****
| 偏回帰係数 | 標準誤差 | t値 | P値 | 標準化偏回帰係数 | |
| d11 | 6.743750 | 2.266673 | 2.9751749 | 0.01392 | 0.4318276 |
| d12 | 17.22500 | 2.423176 | 7.1084399 | 0.00003 | 0.9956292 |
| d21 | 2.617500 | 2.349356 | 1.1141350 | 0.29128 | 0.1612812 |
| d22 | 4.703750 | 2.214258 | 2.1243010 | 0.05959 | 0.2898286 |
| 定数項 | 8.668750 | 2.266673 | 3.8244371 | 0.00335 | |
| t値の自由度は 10 | |||||
偏回帰係数の解釈は以下のようになる。
元のアイテム変数 xi は,2 個のダミー変数 di1 と di2 を使って表現されている(i = 1, 2)。それぞれのダミー変数に対する偏回帰係数を bi1 ,bi2 とすると,予測値は
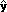 = d11・b11 + d12・b12 + d21・b21 + d22・b22 + 定数項 であらわされる。
= d11・b11 + d12・b12 + d21・b21 + d22・b22 + 定数項 であらわされる。x1 が 1 という値を取るときは,d11 = 0,d12 = 0 であるから,予測値に寄与する値は 0・6.74375 + 0・17.225 = 0 である。
x1 が 2 という値を取るときは,d11 = 1,d12 = 0 であるから,予測値に寄与する値は 1・6.74375 + 0・17.225 = 6.74375 である。すなわち,この場合は x1 = 1 の場合に比べて予測値は 6.74375 大きくなる。
x1 が 3 という値を取るときは,d11 = 0,d12 = 1 であるから,予測値に寄与する値は 0・6.74375 + 1・17.225 = 17.225 である。すなわち,この場合は x1 = 1 の場合に比べて予測値は 17.225 大きくなる。
標準化偏回帰係数の大きさからいうと,予測をするために最も重要なのは d12 であり,次いで d11 である(これらに対する P 値が小さいので,これらの係数が 0 でないといってよいことがわかる)。d22 ,d21 はそれらに比べて予測という観点からはあまり重要ではないことがわかる(これらに対する P 値が大きいので,これらの係数は 0 でないととはいえないということがわかる)。
***** 分散分析表 *****
|
P 値が 小さいので(例えば 5% の有意水準で検定すると),この重回帰式により十分予測できるといえる。 | ||||||||||||||||||||||||||||||||||||||
|
重相関係数,決定係数の値は数量化 I 類による結果と全く同じになる |
***** 従属変数の観察値,予測値および標準化残差 *****
|
予測値は数量化 I 類による結果と全く同じになる。 結局,偏回帰係数の値とノーマライズドカテゴリースコアの値は異なるように見えるが,定数項を含めた調整の後では全く同じ予測値を与える重みであることが分かる。 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
***** 予測値と観察値のプロット *****
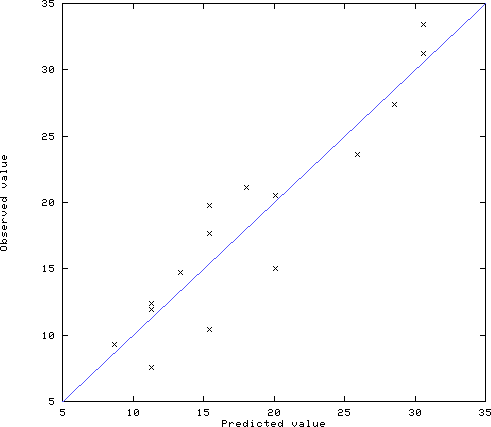 |
予測値と観察値はほぼ傾き1の直線の近辺にあり,予測が比較的うまくいっている(数量化 I 類の結果と全く同じ図である)。 |
- ダミー変数を用いた重回帰分析による分析の例のページへのリンク
