数量化 II 類
カテゴリーデータを説明変数として群を判別する。
ダミー変数を用いる判別分析と等価な解析手法である(解説)。
説明変数 Xi( i = 1, 2, ... , p )が,それぞれ mi 個の選択肢を持つ( このような変数を特にアイテム変数と呼ぼう )。
各選択肢が選ばれたら 1,選ばれなかったら 0 をとるような Σ mi 個の変数 Cij( i = 1, 2, ... , p; j = 1, 2, ... , mi )を定義する。
ここで,各カテゴリーに特定の数値 aij( i = 1, 2, ... , p;j = 1, 2, ... , mi )を割当て,S = Σ Σ aij Cij というサンプルスコア( 判別値 )を計算して各ケースがどの群に属するかを判別しようと考える。
表 1 に示した例においてみてみると,例えば 1 番目のケースの判別をするために a11 + a22 + a32 を使用するわけである。
| 従属変数 (群変数) | 説明変数(カテゴリー変数) | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X1 | X2 | X3 | ||||||||||||
| Y1 | Y2 | Y3 | C11 | C12 | C13 | C21 | C22 | C23 | C24 | C31 | C32 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | |||
| 0 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | |||
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | |||
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | |||
| : | ||||||||||||||
| カテゴリーに 与えられる数値 | a11 | a12 | a13 | a21 | a22 | a23 | a24 | a31 | a32 | |||||
各カテゴリーにどのような数値を与えたらよいかは,Cij を独立変数として以下のような判別式を求めることに帰着できる。
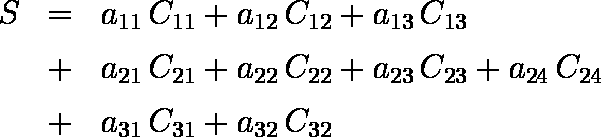
ただし,各説明変数において情報が冗長であるので,各説明変数から 1 個ずつカテゴリーを消去した判別分析を行う( 例えば, C11 と C12 が 0 ならC13 が 1 であることはただちにわかる )。
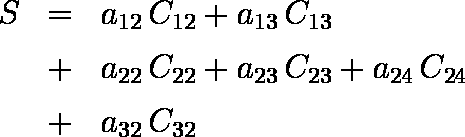
なお,以上で求めた各カテゴリーに与える数値は,各説明変数ごとに平均値がゼロになるように正規化されて利用される。
補足説明
- 連続変数をカテゴリー化して用いる場合には,カテゴリー数が少なすぎないようにしなければならない( 多すぎても困る )。また,カテゴリー化は妥当な分割点で行ったほうがよい( 例えば 2 峰性データならその中点,正常範囲が決っているならその前後など )。
- 得られた判別関数は,分析に使用したケースについて最適のものであるが,別のケース群に適用しても有用であるかどうかはわからない。例えば,ある医療機関に受療した患者に適用できても,別の医療機関の受療患者には適用できないかもしれない。得られた判別関数が他の集団でも有用であるかどうか(交差妥当性を持つかどうか)について検討したほうがよい。
- 交差妥当性を検証するのはなかなかたいへんな場合がある。そのため,便法として折半法と呼ばれる方法がある。この方法は,既存のケースを無作為に半分ずつに分け,一方のケースを用いて判別関数を作り,もう一方のケースを得られた判別関数で判別し正判別率を検討するものである。折半法を用いるには,既存のケース数がある程度多くなければならない。
- 数量化II類のページへのリンク
