ハッシュ‐ひょう〔‐ヘウ〕【ハッシュ表】
読み方:はっしゅひょう
ハッシュ表
【英】:hash table
値(キー)をもつ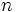 個の要素の集合に対し, 挿入・削除・検索の3つの機能を高速化したデータ構造. 値をハッシュキーと呼ばれるいくつかのキーで分類し, それぞれの要素を連結リストなどにより保持する. 挿入と削除をO
個の要素の集合に対し, 挿入・削除・検索の3つの機能を高速化したデータ構造. 値をハッシュキーと呼ばれるいくつかのキーで分類し, それぞれの要素を連結リストなどにより保持する. 挿入と削除をO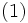 時間で行い, 検索は, 最悪の場合はO
時間で行い, 検索は, 最悪の場合はO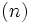 となるが, ハッシュキーを適切に設定すれば平均的に O となることが多い. 辞書データの保持に多く使われ, 辞書のデータを頭文字をハッシュキーとして保持する, などの例がある.
となるが, ハッシュキーを適切に設定すれば平均的に O となることが多い. 辞書データの保持に多く使われ, 辞書のデータを頭文字をハッシュキーとして保持する, などの例がある.
| 組合せ最適化: | データ構造 ナップサック問題 ネットワークフロー問題 ハッシュ表 パーフェクトグラフ パーフェクトグラフ予想 ヒープ |
ハッシュテーブル
(ハッシュ表 から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2022/10/18 03:00 UTC 版)

|
この記事は検証可能な参考文献や出典が全く示されていないか、不十分です。(2016年9月)
|

ハッシュテーブル (英: hash table) は、キーと値の組(エントリと呼ぶ)を複数個格納し、キーに対応する値をすばやく参照するためのデータ構造。ハッシュ表ともいう。ハッシュテーブルは連想配列や集合の効率的な実装のうち1つである。
概要
ハッシュテーブルはキーをもとに生成されたハッシュ値を添え字とした配列である。通常、配列の添え字には非負整数しか扱えない。そこで、キーを要約する値であるハッシュ値を添え字として値を管理することで、検索や追加を要素数によらず定数時間O(1)で実現する。しかしハッシュ関数の選び方(例えば、異なるキーから頻繁に同じハッシュ値が生成される場合)によっては、性能が劣化して最悪の場合O(n)となってしまう。
衝突処理
複数の異なるキーが同じハッシュ値になることを衝突 (collision) と呼ぶ。キーの分布が予めわからない場合、衝突を避けることはできない。同じハッシュ値となるキーを同族キーと呼ぶ。衝突が発生したときの対処の方法は、開番地法と連鎖法に大別される。
連鎖法
衝突を起こしたキー同士をポインタでつなぐ方式を連鎖法と呼ぶ。テーブルの各番地にはキーそのものではなく、同族キーを保持するリンクリストを格納する。
開番地法
衝突が発生した際、テーブル中の空いている別の番地を探す方式を開番地法と呼ぶ。その方法としてハッシュ関数とは別の関数を用いて次の候補となる番地を求める。別の番地を探す関数は繰り返し適用することによってテーブル内の全ての番地を走査できるように選ぶ。
実装方法
連鎖法の一つの実装例を示す。まず、ルート配列と呼ばれる要素数 N の配列を一つ用意する。ルート配列の各要素は、リスト(便宜上エントリリストと呼ぶ)とする。エントリリストには、少数のエントリを格納する。
エントリを格納する場合、エントリのキーをもとにハッシュ関数を用いてハッシュ値を生成する。ハッシュ関数は 0 から N - 1 までの整数値を生成するものであって、一様な分布と高速な計算が要求される。ハッシュ値を i とするとき、ルート配列上の i 番目のエントリリストにこのエントリを格納する。衝突が発生したとき、それらのエントリは同一のエントリリストに格納される。
あるキーをもつエントリを検索する場合、そのキーからハッシュ値を生成する。ハッシュ値を j とするとき、ルート配列上の j 番目のエントリリストに入っているエントリを一つずつ検索し、キーが一致しているものを取り出す。ルート配列上のエントリリストが高速でアクセスできる必要がある。
ハッシュテーブルの自動拡張
ハッシュテーブルはエントリの数が配列のサイズに近づくほど衝突の確率が高くなり、性能が悪化してしまう。この比率をload factor(座席利用率)と呼び、n/Nの形で表す。nはエントリの数、Nは配列のサイズを指す。
連鎖法の場合はload factorの増加に対して線形に性能が悪化する。しかし開番地法の場合は衝突したキーが配列の空いた番地に格納されるため、load factorが0.8を超える付近で性能が急激に悪化する。
この問題を回避するため、load factorが一定を超えた場合に、より大きいサイズのハッシュテーブルを用意して格納し直す操作が必要となる。これをリハッシュ (rehash) と呼ぶ。この操作はすべての要素のハッシュ値を再計算して新たなハッシュテーブルに格納するためO(n)であるが、配列のサイズを指数的に拡張する事で、動的配列の末尾追加操作と同様に償却解析によって計算量をO(1)とみなす事ができる。
より単純な回避方法として、あらかじめ想定されるエントリの数に対して十分に大きなサイズの配列を用意する方法もあるが、エントリの数を事前に想定できない場合には適用できない。
全要素の列挙
順序保証のない列挙
最も単純な実装として、ハッシュテーブルのルート配列上を 0 から N - 1 まで走査し、その中に存在するエントリを列挙する方法がある。連鎖法の場合は見つかったエントリリストをさらにたどる必要がある。しかしこの方法で列挙した場合、各エントリはハッシュ関数によって格納位置を決められているために、全く意味を持たない順序で要素が列挙される。これはランダムな順序という意味ではない。利用方法によっては列挙操作が追加した順序を保持しているかのように見えるため、ハッシュテーブルの利用者が誤解する場合がある。この実装による列挙の計算量はルート配列のサイズ N と連鎖法でのルート配列上にないエントリリストの数 m との合計O(N + m)となる。そのため、ルート配列をあらかじめ大きなサイズで確保しているとこの実装での列挙に時間がかかる。
追加した順序での列挙
追加した順序で要素を列挙する実装方法として、各エントリに追加順を保持するリンクリストのポインタを別に持たせ、列挙する際はそちらのポインタをたどる方法がある。検索・追加操作のみならば単方向リストで実現可能だが、削除操作もサポートする場合は双方向リストで実装しなければO(1)での操作を実現できない。JavaのLinkedHashMapはこの実装であり、その他言語でも利便性からハッシュテーブルが標準で追加順を保証している事がある。欠点として、各エントリに別のリンクリスト用ポインタが必要なためにメモリ消費量が増加する。
プログラミング言語におけるハッシュテーブルの実装
- Javaにおける
HashMapLinkedHashMapHashtable - AWKにおける連想配列
- PerlにおけるHash
- JavaScriptにおけるオブジェクト
- Pythonにおける辞書
- C++のSTLの
std::unordered_map - Rubyの
Hashクラス - Common Lispにおける
hash-tableクラス - CLI (Common Language Infrastructure) の
System.Collections.Hashtable,System.Collections.Specialized.ListDictionary,System.Collections.Specialized.HybridDictionary,System.Collections.Generic.Dictionary<TKey, TValue> - RustのHashMap
- Nimの
std/tables
脚注
関連項目
- ハッシュ表のページへのリンク
