GS-4150, Bullet 3 OpenCL Rigid Body Simulation, by Erwin Coumans
2 likes5,272 views

The document outlines the technical details and applications of the Bullet 3 OpenCL™ Rigid Body Simulation developed by AMD, focusing on real-time collision detection and dynamics libraries used in various industries such as film and gaming. It discusses GPU-based methods for collision detection, constraint solving, and the integration of these processes within a computing environment. Additionally, the document includes a disclaimer regarding the accuracy of the information presented and the potential liabilities associated with its use.




![C/C++ VERSUS OPENCL™
void integrateTransforms(Body* bodies, int numNodes, float timeStep)
{
for (int nodeID=0;nodeId<numNodes;nodeID++) {
if( bodies[nodeID].m_invMass != 0.f) {
bodies[nodeID].m_pos += bodies[nodeID].m_linVel * timeStep;
}
}
__kernel void integrateTransformsKernel( __global Body* bodies, int numNodes, float timeStep)
{
int nodeID = get_global_id(0);
if( nodeID < numNodes && (bodies[nodeID].m_invMass != 0.f)) {
bodies[nodeID].m_pos += bodies[nodeID].m_linVel * timeStep;
}
}
7 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
One to One mapping
Read Compute Write](https://image.slidesharecdn.com/gs-4150erwincoumans-131122134708-phpapp02/85/GS-4150-Bullet-3-OpenCL-Rigid-Body-Simulation-by-Erwin-Coumans-7-320.jpg)

![UPDATE ORIENTATION
__kernel void integrateTransformsKernel( __global Body* bodies,const int numNodes, float timeStep, float angularDamping, float4 gravityAcceleration)
{
int nodeID = get_global_id(0);
if( nodeID < numNodes && (bodies[nodeID].m_invMass != 0.f))
{
bodies[nodeID].m_pos += bodies[nodeID].m_linVel * timeStep;
//linear velocity
bodies[nodeID].m_linVel += gravityAcceleration * timeStep;
//apply gravity
float4 angvel = bodies[nodeID].m_angVel;
//angular velocity
bodies[nodeID].m_angVel *= angularDamping;
//add some angular damping
float4 axis;
float fAngle = native_sqrt(dot(angvel, angvel));
if(fAngle*timeStep> BT_GPU_ANGULAR_MOTION_THRESHOLD)
//limit the angular motion
fAngle = BT_GPU_ANGULAR_MOTION_THRESHOLD / timeStep;
if(fAngle < 0.001f)
axis = angvel * (0.5f*timeStep-(timeStep*timeStep*timeStep)*0.020833333333f * fAngle * fAngle);
else
axis = angvel * ( native_sin(0.5f * fAngle * timeStep) / fAngle);
float4 dorn = axis;
dorn.w = native_cos(fAngle * timeStep * 0.5f);
float4 orn0 = bodies[nodeID].m_quat;
float4 predictedOrn = quatMult(dorn, orn0);
predictedOrn = quatNorm(predictedOrn);
bodies[nodeID].m_quat=predictedOrn;
//update the orientation
}
}
See opencl/gpu_rigidbody/kernels/integrateKernel.cl
9 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL](https://image.slidesharecdn.com/gs-4150erwincoumans-131122134708-phpapp02/85/GS-4150-Bullet-3-OpenCL-Rigid-Body-Simulation-by-Erwin-Coumans-9-320.jpg)





![COMPUTE PAIRS BRUTE FORCE
__kernel void computePairsKernelOriginal( __global const btAabbCL* aabbs,
__global int2* pairsOut, volatile __global int* pairCount,
int numObjects, int axis, int maxPairs)
{
int i = get_global_id(0);
if (i>=numObjects)
return;
for (int j=0;j<numObjects;j++)
{
if ( i != j && TestAabbAgainstAabb2GlobalGlobal(&aabbs[i],&aabbs[j])) {
int2 myPair;
myPair.x = aabbs[i].m_minIndices[3]; myPair.y = aabbs[j].m_minIndices[3];
int curPair = atomic_inc (pairCount);
if (curPair<maxPairs)
pairsOut[curPair] = myPair; //flush to main memory
}
}
18 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
Scatter operation](https://image.slidesharecdn.com/gs-4150erwincoumans-131122134708-phpapp02/85/GS-4150-Bullet-3-OpenCL-Rigid-Body-Simulation-by-Erwin-Coumans-18-320.jpg)
![COMPUTE PAIRS 1-AXIS SORT
__kernel void computePairsKernelOriginal( __global const btAabbCL* aabbs,
__global int2* pairsOut, volatile __global int* pairCount,
int numObjects, int axis, int maxPairs)
{
int i = get_global_id(0);
if (i>=numObjects)
return;
for (int j=i+1;j<numObjects;j++)
{
if(aabbs[i].m_maxElems[axis] < (aabbs[j].m_minElems[axis]))
break;
if (TestAabbAgainstAabb2GlobalGlobal(&aabbs[i],&aabbs[j])) {
int2 myPair;
myPair.x = aabbs[i].m_minIndices[3]; myPair.y = aabbs[j].m_minIndices[3];
int curPair = atomic_inc (pairCount);
if (curPair<maxPairs)
pairsOut[curPair] = myPair; //flush to main memory
}
}
22 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL](https://image.slidesharecdn.com/gs-4150erwincoumans-131122134708-phpapp02/85/GS-4150-Bullet-3-OpenCL-Rigid-Body-Simulation-by-Erwin-Coumans-22-320.jpg)





![TREE VERSUS TREE: TANDEM TRAVERSAL
for (int p=0;p<numSubTreesA;p++) {
for (int q=0;q<numSubTreesB;q++) {
b3Int2 node0; node0.x = startNodeIndexA;node0.y = startNodeIndexB;
nodeStack[depth++]=node0; depth = 1;
do {
b3Int2 node = nodeStack[--depth];
if (nodeOverlap){
if(isInternalA && isInternalB){
nodeStack[depth++] = b3MakeInt2(nodeAleftChild, nodeBleftChild);
nodeStack[depth++] = b3MakeInt2(nodeArightChild, nodeBleftChild);
nodeStack[depth++] = b3MakeInt2(nodeAleftChild, nodeBrightChild);
nodeStack[depth++] = b3MakeInt2(nodeArightChild, nodeBrightChild);
} else {
if (isLeafA && isLeafB) processLeaf(…)
else { …} //see actual code
}
} while (depth);
See __kernel void findCompoundPairsKernel( __global const int4* pairs … in
‒ in bullet3srcBullet3OpenCLNarrowphaseCollisionkernels/sat.cl
34 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL](https://image.slidesharecdn.com/gs-4150erwincoumans-131122134708-phpapp02/85/GS-4150-Bullet-3-OpenCL-Rigid-Body-Simulation-by-Erwin-Coumans-34-320.jpg)



![CPU SEQUENTIAL BATCH CREATION
while( nIdxSrc ) {
nIdxDst = 0;
int nCurrentBatch = 0;
for(int i=0; i<N_FLG/32; i++) flg[i] = 0; //clear flag
for(int i=0; i<nIdxSrc; i++)
{
int idx = idxSrc[i]; btAssert( idx < n );
//check if it can go
int aIdx = cs[idx].m_bodyAPtr & FLG_MASK;
int bIdx = cs[idx].m_bodyBPtr & FLG_MASK;
u32 aUnavailable = flg[ aIdx/32 ] & (1<<(aIdx&31));u32 bUnavailable = flg[ bIdx/32 ] & (1<<(bIdx&31));
if( aUnavailable==0 && bUnavailable==0 )
{
flg[ aIdx/32 ] |= (1<<(aIdx&31));
flg[ bIdx/32 ] |= (1<<(bIdx&31));
cs[idx].getBatchIdx() = batchIdx;
sortData[idx].m_key = batchIdx; sortData[idx].m_value = idx;
nCurrentBatch++;
if( nCurrentBatch == simdWidth ) {
nCurrentBatch = 0;
for(int i=0; i<N_FLG/32; i++) flg[i] = 0;
}
}
else {
idxDst[nIdxDst++] = idx;
}
}
swap2( idxSrc, idxDst ); swap2( nIdxSrc, nIdxDst );
batchIdx ++;
}
42 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL](https://image.slidesharecdn.com/gs-4150erwincoumans-131122134708-phpapp02/85/GS-4150-Bullet-3-OpenCL-Rigid-Body-Simulation-by-Erwin-Coumans-42-320.jpg)






GS-4150, Bullet 3 OpenCL Rigid Body Simulation, by Erwin Coumans
- 1. BULLET 3 OPENCL™ RIGID BODY SIMULATION ERWIN COUMANS, AMD
- 2. DISCLAIMER & ATTRIBUTION The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time to the content hereof without obligation of AMD to notify any person of such revisions or changes. AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF MERCHANTABILITY OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY DIRECT, INDIRECT, SPECIAL OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. ATTRIBUTION © 2013 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo and combinations thereof are trademarks of Advanced Micro Devices, Inc. in the United States and/or other jurisdictions. OpenCL™ is a trademark of Apple Inc. Windows® and DirectX® are trademarks of Microsoft Corp. Linux is a trademark of Linus Torvalds. Other names are for informational purposes only and may be trademarks of their respective owners. 2 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 3. AGENDA Introduction, Particles, Rigid Bodies GPU Collision Detection GPU Constraint Solving 3 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 4. BULLET 2.82 AND BULLET 3 OPENCL™ ALPHA Real-time C++ collision detection and rigid body dynamics library Used in movies ‒ Maya, Houdini, Cinema 4D, Blender, Lightwave, Carrara, Posed 3D, thinking Particles, etc ‒ Disney Animation (Bolt), PDI Dreamworks (Shrek, How to train your dragon), Sony Imageworks (2012), Games ‒ GTA IV, Disney Toystory 3, Cars 2, Riptide GP, GP2 Industrial applications, Robotics ‒ Siemens NX9 MCD, Gazebo 4 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
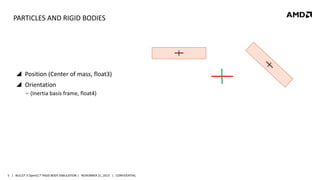
- 5. PARTICLES AND RIGID BODIES Position (Center of mass, float3) Orientation ‒ (Inertia basis frame, float4) 5 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
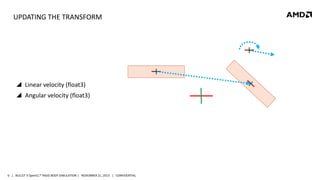
- 6. UPDATING THE TRANSFORM Linear velocity (float3) Angular velocity (float3) 6 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 7. C/C++ VERSUS OPENCL™ void integrateTransforms(Body* bodies, int numNodes, float timeStep) { for (int nodeID=0;nodeId<numNodes;nodeID++) { if( bodies[nodeID].m_invMass != 0.f) { bodies[nodeID].m_pos += bodies[nodeID].m_linVel * timeStep; } } __kernel void integrateTransformsKernel( __global Body* bodies, int numNodes, float timeStep) { int nodeID = get_global_id(0); if( nodeID < numNodes && (bodies[nodeID].m_invMass != 0.f)) { bodies[nodeID].m_pos += bodies[nodeID].m_linVel * timeStep; } } 7 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL One to One mapping Read Compute Write
- 8. OPENCL™ PARTICLES 8 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 9. UPDATE ORIENTATION __kernel void integrateTransformsKernel( __global Body* bodies,const int numNodes, float timeStep, float angularDamping, float4 gravityAcceleration) { int nodeID = get_global_id(0); if( nodeID < numNodes && (bodies[nodeID].m_invMass != 0.f)) { bodies[nodeID].m_pos += bodies[nodeID].m_linVel * timeStep; //linear velocity bodies[nodeID].m_linVel += gravityAcceleration * timeStep; //apply gravity float4 angvel = bodies[nodeID].m_angVel; //angular velocity bodies[nodeID].m_angVel *= angularDamping; //add some angular damping float4 axis; float fAngle = native_sqrt(dot(angvel, angvel)); if(fAngle*timeStep> BT_GPU_ANGULAR_MOTION_THRESHOLD) //limit the angular motion fAngle = BT_GPU_ANGULAR_MOTION_THRESHOLD / timeStep; if(fAngle < 0.001f) axis = angvel * (0.5f*timeStep-(timeStep*timeStep*timeStep)*0.020833333333f * fAngle * fAngle); else axis = angvel * ( native_sin(0.5f * fAngle * timeStep) / fAngle); float4 dorn = axis; dorn.w = native_cos(fAngle * timeStep * 0.5f); float4 orn0 = bodies[nodeID].m_quat; float4 predictedOrn = quatMult(dorn, orn0); predictedOrn = quatNorm(predictedOrn); bodies[nodeID].m_quat=predictedOrn; //update the orientation } } See opencl/gpu_rigidbody/kernels/integrateKernel.cl 9 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 10. UPDATE TRANSFORMS, HOST SETUP ciErrNum = clSetKernelArg(g_integrateTransformsKernel, 0, sizeof(cl_mem), &bodies); ciErrNum = clSetKernelArg(g_integrateTransformsKernel, 1, sizeof(int), &numBodies); ciErrNum = clSetKernelArg(g_integrateTransformsKernel, 1, sizeof(float), &deltaTime); ciErrNum = clSetKernelArg(g_integrateTransformsKernel, 1, sizeof(float), &angularDamping); ciErrNum = clSetKernelArg(g_integrateTransformsKernel, 1, sizeof(float4), &gravityAcceleration); size_t workGroupSize = 64; size_t numWorkItems = workGroupSize*((m_numPhysicsInstances + (workGroupSize)) / workGroupSize); if (workGroupSize>numWorkItems) workGroupSize=numWorkItems; ciErrNum = clEnqueueNDRangeKernel(g_cqCommandQue, g_integrateTransformsKernel, 1, NULL, &numWorkItems, &workGroupSize,0 ,0 ,0); 10 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 11. MOVING THE CODE TO GPU Create an OpenCL™ wrapper ‒ Easier use, fits code style, extra features, learn the API Replace C++ by C Move data to contiguous memory Replace pointers by indices Exploit the GPU hardware… 11 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 12. SHARING DATA STRUCTURES AND CODE BETWEEN OPENCL™ AND C/C++ #include "Bullet3Collision/NarrowPhaseCollision/shared/b3RigidBodyData.h" #include "Bullet3Dynamics/shared/b3IntegrateTransforms.h" __kernel void integrateTransformsKernel( __global b3RigidBodyData_t* bodies,const int numNodes, float timeStep, float angularDamping, float4 gravityAcceleration) { int nodeID = get_global_id(0); if( nodeID < numNodes) { integrateSingleTransform(bodies,nodeID, timeStep, angularDamping,gravityAcceleration); } } 12 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 13. PREPROCESSING OF KERNELS WITH INCLUDES IN SINGLE HEADER FILE We want the option of embedding kernels in our C/C++ program Expand all #include files, recursively into a single stringified header file ‒ This header can be used in OpenCL™ kernels and in regular C/C++ files too ‒ Kernel binary is cached and cached version is unvalidated based on time stamp of embedded kernel file Premake, Lua and a lcpp: very small and simple C pre-processor written in Lua ‒ See https://github.com/willsteel/lcpp 13 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 14. HOST, DEVICE, KERNELS, WORK ITEMS Host Device (GPU) CPU L2 cache Global Host Memory 14 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL Global Device Memory
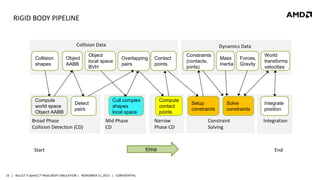
- 16. RIGID BODY PIPELINE Collision Data Collision shapes Compute world space Object AABB Object AABB Object local space BVH Detect pairs Broad Phase Collision Detection (CD) Dynamics Data Overlapping pairs Contact points Cull complex shapes local space Mid Phase CD Start 16 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL Compute contact points Narrow Phase CD time Constraints (contacts, joints) Setup constraints Mass Inertia Forces, Gravity Solve constraints Constraint Solving World transforms velocities Integrate position Integration End
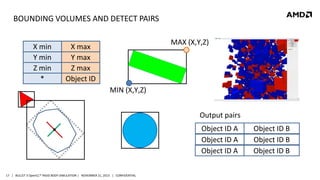
- 17. BOUNDING VOLUMES AND DETECT PAIRS X min Y min Z min * MAX (X,Y,Z) X max Y max Z max Object ID MIN (X,Y,Z) Output pairs Object ID A Object ID A Object ID A 17 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL Object ID B Object ID B Object ID B
- 18. COMPUTE PAIRS BRUTE FORCE __kernel void computePairsKernelOriginal( __global const btAabbCL* aabbs, __global int2* pairsOut, volatile __global int* pairCount, int numObjects, int axis, int maxPairs) { int i = get_global_id(0); if (i>=numObjects) return; for (int j=0;j<numObjects;j++) { if ( i != j && TestAabbAgainstAabb2GlobalGlobal(&aabbs[i],&aabbs[j])) { int2 myPair; myPair.x = aabbs[i].m_minIndices[3]; myPair.y = aabbs[j].m_minIndices[3]; int curPair = atomic_inc (pairCount); if (curPair<maxPairs) pairsOut[curPair] = myPair; //flush to main memory } } 18 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL Scatter operation
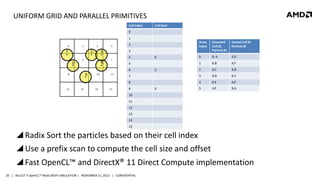
- 19. DETECT PAIRS Uniform Grid ‒ Very fast ‒ Suitable for GPU ‒ Object size restrictions 0 1 2 F C E 5 D B A 8 3 10 7 11 Can be mixed with other algorithms 12 13 See bullet3srcBullet3OpenCLBroadphaseCollisionb3GpuGridBroadphase.cpp 19 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL 14 15
- 20. UNIFORM GRID AND PARALLEL PRIMITIVES Radix Sort the particles based on their cell index Use a prefix scan to compute the cell size and offset Fast OpenCL™ and DirectX® 11 Direct Compute implementation 20 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
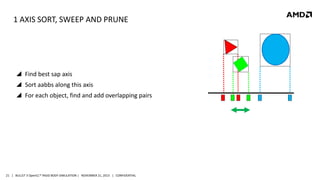
- 21. 1 AXIS SORT, SWEEP AND PRUNE Find best sap axis Sort aabbs along this axis For each object, find and add overlapping pairs 21 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 22. COMPUTE PAIRS 1-AXIS SORT __kernel void computePairsKernelOriginal( __global const btAabbCL* aabbs, __global int2* pairsOut, volatile __global int* pairCount, int numObjects, int axis, int maxPairs) { int i = get_global_id(0); if (i>=numObjects) return; for (int j=i+1;j<numObjects;j++) { if(aabbs[i].m_maxElems[axis] < (aabbs[j].m_minElems[axis])) break; if (TestAabbAgainstAabb2GlobalGlobal(&aabbs[i],&aabbs[j])) { int2 myPair; myPair.x = aabbs[i].m_minIndices[3]; myPair.y = aabbs[j].m_minIndices[3]; int curPair = atomic_inc (pairCount); if (curPair<maxPairs) pairsOut[curPair] = myPair; //flush to main memory } } 22 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
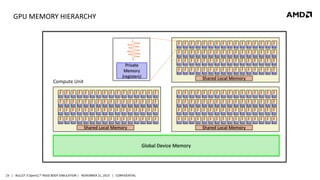
- 23. GPU MEMORY HIERARCHY Private Memory (registers) Shared Local Memory Compute Unit Shared Local Memory Shared Local Memory Global Device Memory 23 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 24. BARRIER A point in the program where all threads stop and wait When all threads in the Work Group have reached the barrier, they can proceed Barrier 24 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 25. KERNEL OPTIMIZATIONS FOR 1-AXIS SORT CONTENT SUBHEADER LOCAL MEMORY block to fetch AABBs and re-use them within a workgroup (barrier) AVOID GLOBAL ATOMICS Use private memory to accumulate overlapping pairs (append buffer) LOCAL ATOMICS Determine early exit condition for all work items within a workgroup 25 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 26. KERNEL OPTIMIZATIONS (1-AXIS SORT) Load balancing ‒ One work item per object, multiple work items for large objects See opencl/gpu_broadphase/kernels/sapFast.cl and sap.cl (contains un-optimized and optimized version of the kernel for comparison) 26 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
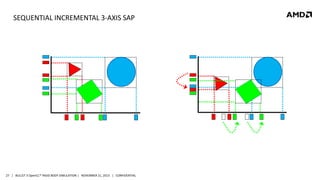
- 27. SEQUENTIAL INCREMENTAL 3-AXIS SAP 27 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
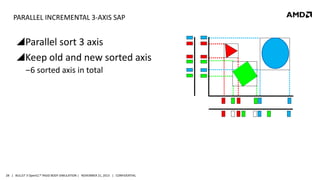
- 28. PARALLEL INCREMENTAL 3-AXIS SAP Parallel sort 3 axis Keep old and new sorted axis ‒6 sorted axis in total 28 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
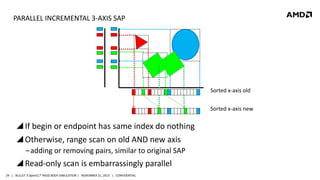
- 29. PARALLEL INCREMENTAL 3-AXIS SAP Sorted x-axis old Sorted x-axis new If begin or endpoint has same index do nothing Otherwise, range scan on old AND new axis ‒adding or removing pairs, similar to original SAP Read-only scan is embarrassingly parallel 29 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
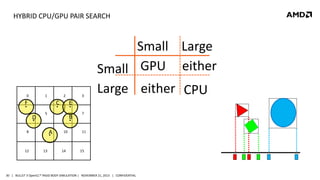
- 30. HYBRID CPU/GPU PAIR SEARCH 0 1 2 F C D 12 E 5 B A 8 13 3 Small Large Small GPU either Large either CPU 10 14 7 11 15 30 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 31. TRIANGLE MESH COLLISION DETECTION 31 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
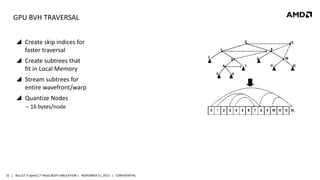
- 32. GPU BVH TRAVERSAL Create skip indices for faster traversal Create subtrees that fit in Local Memory Stream subtrees for entire wavefront/warp Quantize Nodes ‒ 16 bytes/node 32 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 33. COMPOUND VERSUS COMPOUND COLLISION DETECTION 33 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 34. TREE VERSUS TREE: TANDEM TRAVERSAL for (int p=0;p<numSubTreesA;p++) { for (int q=0;q<numSubTreesB;q++) { b3Int2 node0; node0.x = startNodeIndexA;node0.y = startNodeIndexB; nodeStack[depth++]=node0; depth = 1; do { b3Int2 node = nodeStack[--depth]; if (nodeOverlap){ if(isInternalA && isInternalB){ nodeStack[depth++] = b3MakeInt2(nodeAleftChild, nodeBleftChild); nodeStack[depth++] = b3MakeInt2(nodeArightChild, nodeBleftChild); nodeStack[depth++] = b3MakeInt2(nodeAleftChild, nodeBrightChild); nodeStack[depth++] = b3MakeInt2(nodeArightChild, nodeBrightChild); } else { if (isLeafA && isLeafB) processLeaf(…) else { …} //see actual code } } while (depth); See __kernel void findCompoundPairsKernel( __global const int4* pairs … in ‒ in bullet3srcBullet3OpenCLNarrowphaseCollisionkernels/sat.cl 34 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 35. CONTACT GENERATION: GPU CONVEX HEIGHTFIELD Dual representation SATHE, R. 2006. Collision detection shader using cube-maps. In ShaderX5, Charles River Media 35 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
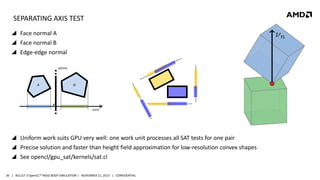
- 36. SEPARATING AXIS TEST Face normal A Face normal B Edge-edge normal plane A B axis Uniform work suits GPU very well: one work unit processes all SAT tests for one pair Precise solution and faster than height field approximation for low-resolution convex shapes See opencl/gpu_sat/kernels/sat.cl 36 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
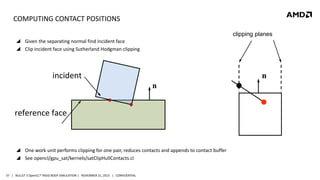
- 37. COMPUTING CONTACT POSITIONS clipping planes Given the separating normal find incident face Clip incident face using Sutherland Hodgman clipping incident n n reference face One work unit performs clipping for one pair, reduces contacts and appends to contact buffer See opencl/gpu_sat/kernels/satClipHullContacts.cl 37 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 38. SAT ON GPU Break the algorithm into pipeline stages, separated into many kernels ‒ findSeparatingAxisKernel ‒ findClippingFacesKernel ‒ clipFacesKernel ‒ contactReductionKernel Concave and compound cases produce even more stages ‒ bvhTraversalKernel,findConcaveSeparatingAxisKernel,findCompoundPairsKernel,processCompoundPairsPrimitiv esKernel,processCompoundPairsKernel,findConcaveSphereContactsKernel,clipHullHullConcaveConvexKernel 38 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
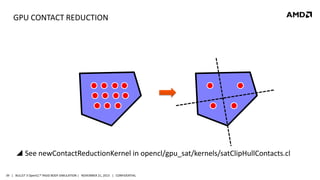
- 39. GPU CONTACT REDUCTION See newContactReductionKernel in opencl/gpu_sat/kernels/satClipHullContacts.cl 39 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
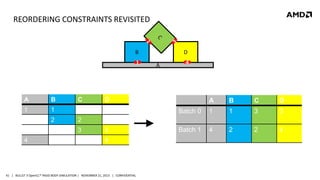
- 41. REORDERING CONSTRAINTS REVISITED B 1 A B 1 1 2 C A 4 D A B C D Batch 0 1 1 3 3 Batch 1 4 2 2 4 2 3 4 D 3 4 41 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 42. CPU SEQUENTIAL BATCH CREATION while( nIdxSrc ) { nIdxDst = 0; int nCurrentBatch = 0; for(int i=0; i<N_FLG/32; i++) flg[i] = 0; //clear flag for(int i=0; i<nIdxSrc; i++) { int idx = idxSrc[i]; btAssert( idx < n ); //check if it can go int aIdx = cs[idx].m_bodyAPtr & FLG_MASK; int bIdx = cs[idx].m_bodyBPtr & FLG_MASK; u32 aUnavailable = flg[ aIdx/32 ] & (1<<(aIdx&31));u32 bUnavailable = flg[ bIdx/32 ] & (1<<(bIdx&31)); if( aUnavailable==0 && bUnavailable==0 ) { flg[ aIdx/32 ] |= (1<<(aIdx&31)); flg[ bIdx/32 ] |= (1<<(bIdx&31)); cs[idx].getBatchIdx() = batchIdx; sortData[idx].m_key = batchIdx; sortData[idx].m_value = idx; nCurrentBatch++; if( nCurrentBatch == simdWidth ) { nCurrentBatch = 0; for(int i=0; i<N_FLG/32; i++) flg[i] = 0; } } else { idxDst[nIdxDst++] = idx; } } swap2( idxSrc, idxDst ); swap2( nIdxSrc, nIdxDst ); batchIdx ++; } 42 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
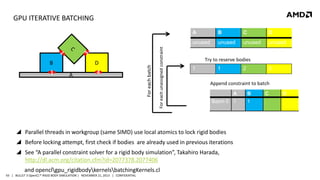
- 43. GPU ITERATIVE BATCHING D 1 4 A For each unassigned constraint B B C D unused For each batch A unused unused unused Try to reserve bodies 1 1 A B Batch 0 1 1 Before locking attempt, first check if bodies are already used in previous iterations See “A parallel constraint solver for a rigid body simulation”, Takahiro Harada, http://dl.acm.org/citation.cfm?id=2077378.2077406 43 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL 3 Append constraint to batch Parallel threads in workgroup (same SIMD) use local atomics to lock rigid bodies and openclgpu_rigidbodykernelsbatchingKernels.cl 2 C D
- 44. GPU PARALLEL TWO STAGE BATCH CREATION Cell size > maximum dynamic object size Constraint are assigned to a cell ‒ based on the center-of-mass location of the first active rigid body of the pair-wise constraint Non-neighboring cells can be processed in parallel 44 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
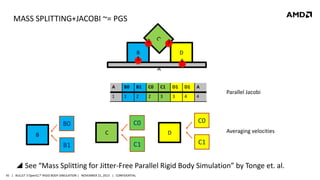
- 45. MASS SPLITTING+JACOBI ~= PGS 2 3 B 1 D 4 A A B0 B1 C0 C1 D1 D1 A 1 1 2 2 3 3 4 4 C B B1 C0 C0 B0 Averaging velocities D C1 Parallel Jacobi C1 See “Mass Splitting for Jitter-Free Parallel Rigid Body Simulation” by Tonge et. al. 45 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 46. GPU NON-CONTACT CONSTRAINTS, JOINTS 46 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 47. GPU NON-CONTACT CONSTRAINTS, JOINTS __kernel void getInfo1Kernel(__global unsigned int* infos, __global b3GpuGenericConstraint* constraints, int numConstraints) __kernel void getInfo2Kernel(__global b3SolverConstraint* solverConstraintRows, .. switch (constraint->m_constraintType) { case B3_GPU_POINT2POINT_CONSTRAINT_TYPE: case B3_GPU_FIXED_CONSTRAINT_TYPE: } getInfo1Kernel and getInfo2Kernel with switch statement replaces virtual methods in Bullet 2.x See bullet3srcBullet3OpenCLRigidBodykernelsjointSolver.cl 47 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 48. DETERMINISTIC RESULTS Projected Gauss Seidel requires solving rows in the same order Sort the constraint rows (contacts, joints) Solve constraint batches in the same order 48 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
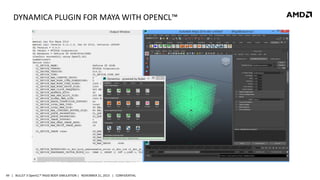
- 49. DYNAMICA PLUGIN FOR MAYA WITH OPENCL™ 49 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
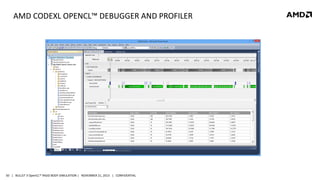
- 50. AMD CODEXL OPENCL™ DEBUGGER AND PROFILER 50 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
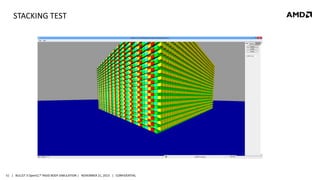
- 51. STACKING TEST 51 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 52. FUTURE WORK DirectX®11 DirectCompute port Multi GPU, multi-core, MPI Move over Bullet 2 to Bullet 3, hybrid of CPU and GPU ‒ Featherstone, direct solvers on CPU Cloth and Fluid simulation, TressFX hair, with two-way interaction Extend GPU-PGS solver to GPU-NNCG ‒ Non-smooth non-linear conjugate gradient solver Improve GPU Ray intersection tests 52 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL
- 53. THANK YOU! Visit http://bulletphysics.org for more information. All source code is available: http://github.com/erwincoumans/bullet3 ‒ Lets you fork, report issues and request features Windows®, Linux®, Mac OSX AMD and NVIDIA GPU ‒ Preferably high-end desktop GPU 53 | BULLET 3 OpenCL™ RIGID BODY SIMULATION | NOVEMBER 21, 2013 | CONFIDENTIAL