かつてはディープラーニング(深層学習)の適用が難しいと言われていた自然言語処理の分野でも、人工知能(AI)が人間の認識精度を上回るようになった。米グーグル(Google)の機械学習手法「BERT」の発表をきっかけに、この1年で状況が激変した。
グーグルが2018年10月に発表したBERTは、文章の「言語らしさ」を予測する言語モデルを「Transformer」というニューラルネットワークを多段に重ねて実装したものである。言語らしさの予測は、AIが単語や文章を理解したり自然な文章を生成したりするうえで必要不可欠な要素である。言語らしさを基準に、単語と単語や文章と文章の関係をベクトルで表現したり、ある単語の次にどの単語が続くべきかを予測したりできるようになるからだ。
言語モデルの応用先としては、機械翻訳や機械読解、質問応答、言葉の言い換え(換言)、表現が異なる2つの文章の意味が同じかどうかの判断(含意関係認識)などがある。グーグルのBERTは自然言語処理の世界に衝撃を与え、論文の発表からわずか1年で2200件以上も他の論文に引用されるほどになった。これは、BERTが応用に関するベンチマークで人間の精度を上回る成果を上げたからだ。
文章読解のスコアで人間超え
具体的には機械読解のベンチマークである「SQuAD 1.1」で人間の精度を上回った。SQuAD 1.1は米スタンフォード大学が作ったベンチマークで、「Wikipedia」の中にある140単語ほどの文章を読み解かせて、その文章に関する質問に回答させる。正答は元の文章の中にフレーズとして存在する。正答の部分を正しく抜き出せるかどうかがポイントとなる。文章と質問、正答の組み合わせは10万件以上あり、クラウドソーシングによって作成した。
スタンフォード大学が人間の被験者にSQuAD 1.1ベンチマークのタスクを解いてもらったところ、元の文章から正答を完全一致で抜き出せたスコア(正答率)は「82.304%」で、部分一致で抜き出せたスコアは「91.221%」だった。それに対してBERTは完全一致のスコアが「87.433%」、部分一致のスコアが「93.160%」で、人間のスコアを上回った。
SQuAD 1.1はタスクとして単純すぎるという指摘もある。SQuAD 1.1よりタスクの難易度が高いベンチマークは「SQuAD 2.0」や「GLUE」など他にもあり、そうしたより難しいベンチマークではBERTは人間を上回れなかった。しかしBERTが一部でも人間をスコアで上回ったことから、この分野の研究が一気に加速し、今ではBERTを改善した手法が、より難しいベンチマークでも人間超えを果たすようになった。
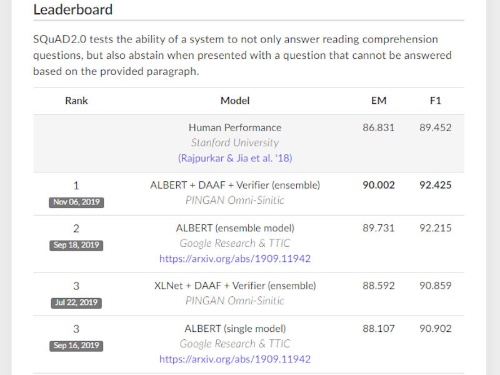
例えばSQuAD 2.0ベンチマーク。SQuAD 1.1は質問の正答が文章の中にフレーズとして必ず存在したが、SQuAD 2.0は正答が文章の中に存在しない「回答不能」の質問も混ざっている。SQuAD 1.1よりタスクの難易度が上だ。このSQuAD 2.0における人間のスコア(正答率)は完全一致が「86.831%」で部分一致が「89.452%」なのに対して、グーグルによるBERTの改良版「ALBERT」のスコアは完全一致が「89.731%」、部分一致が「92.215%」と人間を上回っている。現在のベンチマークの首位はALBERTにさらに改良を加えた中国・平安科技(Ping An Technology)で、スコアは完全一致が「90.002%」、部分一致が「92.425%」である。
SQuADは文章読解だけのベンチマークだ。それに対してGLUEは自然言語処理の総合的なベンチマークであり、読解以外に言い換えや含意関係認識、単語埋め込み、チューリングテストの高難易度版である「ウィノグラード・スキーマ・チャレンジ」などより難しいタスクを含む。GLUEベンチマークは自然言語処理技術の進化を踏まえ、米ニューヨーク大学(NYU)、米ワシントン大学(UW)、グーグル系の英ディープマインド(DeepMind)が連携して2018年4月に作った。





















































