クラスター‐ぶんせき【クラスター分析】
クラスター分析
クラスター(Cluster)はもともとはブドウの房の意味。群れ、集団、集落のこと。住んでいる地域、年令・性別・年収などの人口統計学的データ、趣味・ライフスタイルなどの心理的特徴をベースにして似たようなグループにくくった固まりをクラスターと表現している。共通した特性によって人々や物事をグループに分ける統計的分析手法。有効な分類軸がわからないデータを、自動的に切り口を探し出してくれる。顧客の行動や興味の特性から分類し、例えば、ヤッピー(Yuppies)としてクラスター化し、そのクラスターをターゲットにしてプロモーションコピーやデザインを行う。クラスター分析の前にクラスター・サンプル(Cluster Sample)の抽出が必要。顧客リストからテストサンプルを選び出す。例えば、10万人から2つの5000サンプルを選び出す場合、まず10万人をランダムに20グループに分ける。つぎに、その20グループから2つのグループを選択する。もし2つのグループが同じような特徴をもつグループであれば、サンプル間のリスポンスの違いは各グループに送ったプロモーションの違いになる。テスト目的に合わせて、多段階でテストサンプルを抽出する方法。
クラスター分析
クラスター分析
似通った個体あるいは変数のグループ化を行うための分析手法である。
クラスター分析の結果は,図 1 のようなデンドログラム(樹状図)として表現される。
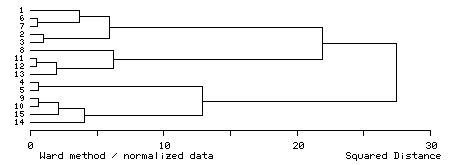 図 1.クラスター分析の結果として得られるデンドログラム |
|---|
個体が似通っているかどうかの判定基準としてはいくつかあるが,取り扱いが容易なユークリッド距離を用いる。
個体のクラスター分析を行う場合には,解析に用いるデータを正規化する場合としない場合では結果がかなり異なることがある。 解析に使用する変数が異なった単位で表されているときには,正規化した方がよいかもしれない。しかし,ある変数が決定的な性質を持つ場合には,正規化することは他の変数と同格に取り扱ってしまうことになるので正規化しない方がよいかもしれない。
n 個の個体について,p 個の変数 Xi1, Xi2, ... , Xip( i = 1,2, ... ,n )があるとする。 初期状態として,n 個のクラスターがあるとする(各クラスターは 1 個体ずつを含むと考える)。
- 第 1 段階
クラスター間のユークリッド平方距離dij2 を計算する。
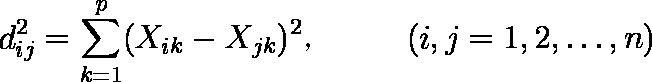
- 第 2 段階
ユークリッド平方距離の最も近いクラスターを併合して,1 つのクラスターとする。
クラスター a とクラスター b が併合されてクラスター c が作られるとする。
dab,dxa,dxb を,クラスター a とクラスター b が併合される前の各クラスター間の距離としたとき,併合後のクラスター c とクラスター x( x ≠ a,x ≠ b )との距離は( 1 ),( 2 )式で表される。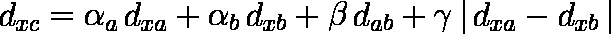 ……( 1 )
……( 1 )
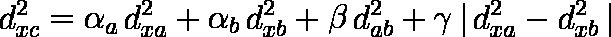 ……( 2 )
……( 2 )
αa,αb,β,γ は表 1 に示すような定数
- 第 3 段階
2 個のクラスターが 1 個のクラスターにまとめられたので,総クラスター数が 1 個減る。
クラスター数が 1 になるまで第 2 段階を繰返す。
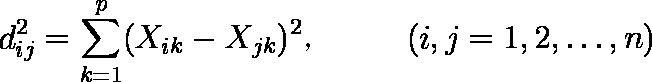
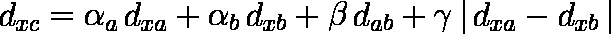 ……
……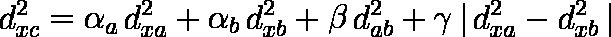 ……
……| αa | αb | β | γ | 使用される式 | |
|---|---|---|---|---|---|
| 最短距離法 | 0.5 | 0.5 | 0 | -0.5 | ( 1 ) |
| 最長距離法 | 0.5 | 0.5 | 0 | 0.5 | ( 1 ) |
| メディアン法 | 0.5 | 0.5 | -0.25 | 0 | ( 1 ) |
| 重心法 | na/nc | nb/nc | -(nanb)/nc2 | 0 | ( 2 ) |
| 群平均法 | na/nc | nb/nc | 0 | 0 | ( 2 ) |
| 可変法 | (1-β*)/2 | (1-β*)/2 | β* | 0 | ( 2 ) |
| ウォード法 | (nx+na)/(nx+nc) | (nx+nb)/(nx+nc) | -nx/(nx+nc) | 0 | ( 2 ) |
β*は1未満の任意の値
( 1 )式または( 2 )式で併合後のユークリッド距離を計算するときの定数 αa,αb,β,γ をどのように選ぶかによって,表 1 に示す 7 種類のクラスター分析が行える。
各手法の分類感度は,クラスターの融合によって空間が拡散される場合に高く,濃縮される場合に低くなる。各手法の特徴は以下の通りである。
| 手法 | 特徴 |
|---|---|
| ウォード法 | 最も明確なクラスターを作る(分類感度が高い)。 |
| 最短距離法 | 分類感度は低く,鎖状のクラスターを作る傾向がある。 |
| 最長距離法 | 空間の拡散が起こり,分類感度は高い。 |
| メディアン法 | 最近隣法と最遠隣法の折衷法である。クラスター間の距離の逆転が生じる場合がある。 |
| 重心法 | クラスター間の距離の逆転が生じる場合がある。 |
| 可変法 | パラメータ(β)の選択によって空間の濃縮・拡散を制御できるので,バラエティーに富んだ結果を生み出す。βとしては1未満の値を指定する。βの値が1に近いほど空間の濃縮が起こる(分類感度が低くなる)。負の値をとれば,空間の拡散が起こる(分類感度が高くなる)。一般に,-0.25〜0の範囲の値を与えるのがよいといわれている。 |
変数のクラスター分析を行う場合には,変数 i と変数 j の相関係数を rij としたとき,2 変数間の距離が次式で表されることになるので,個体のクラスター分析と同じように取り扱うことができる。

クラスター分析
【英】:cluster analysis
概要
解析の対象すべてをいくつかの群に分けて, 何らかの基準にしたがって似ているものが同じ群に入るように分類する方法. 群をクラスターというが, クラスターの集合は, 対象すべてからなる集合の分割に当たる. クラスターの数と分割に対する評価基準が与えられているとき, 最適な分割を求めるのは, 組合せ最適化問題になる. 対象1個ずつの状態から, 選ばれた2つのクラスターを結合することを繰りかえす階層的方法が多数提案されている.
詳説
現象解析の基本操作の一つである分類を行う方法に関わる探索的方法論の総称がクラスター分析である. 博物学, 考古学, 生物分類学, 計量心理学など適用分野がきわめて多岐にわたることが特徴である. 欧州圏では, 自動分類法(automatic classification)と呼称することが多い. 分類操作とは, 解析の対象すべてをいくつかの群に分けて, 何らかの基準に従って似ているものが同じ群に入っているようにすることである. 群をクラスターという.
すべての対象の集合を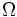 とする. これの部分集合の集合
とする. これの部分集合の集合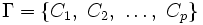 が, 次の条件を満たすとき,の分割という.
が, 次の条件を満たすとき,の分割という.

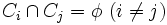
このとき, 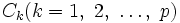 がクラスターであり,クラスター分析の目的は, 与えられた基準に従って, 最適な分割を求めることである.
がクラスターであり,クラスター分析の目的は, 与えられた基準に従って, 最適な分割を求めることである.
分類の目的によって, 分類結果, すなわち, 得られた分割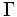 に対する評価基準が定まる. これは, 目的関数で示される. たとえば, 同じクラスターに属する対象は, お互いに類似しているほうがよいのであれば, 同じクラスターに属する2対象間の類似度の最小値を目的関数にして, それをできるだけ大きくすればよいし, 異なるクラスターに属する対象は, できるだけ類似していないほうがよければ, 異なるクラスターに属する2対象間の類似度の最大値を目的関数にして, それをできるだけ小さくすればよい.
に対する評価基準が定まる. これは, 目的関数で示される. たとえば, 同じクラスターに属する対象は, お互いに類似しているほうがよいのであれば, 同じクラスターに属する2対象間の類似度の最小値を目的関数にして, それをできるだけ大きくすればよいし, 異なるクラスターに属する対象は, できるだけ類似していないほうがよければ, 異なるクラスターに属する2対象間の類似度の最大値を目的関数にして, それをできるだけ小さくすればよい.
[分類手法]
分類方法は, いろいろ提案されているが, 大きく, 階層的分類法 (hierarchical classification) と非階層的分類法に分けられ, 階層的分類法は, さらに, 凝集型 (agglomerative type) と分枝型 (divisible type) に分けられる.
予め定めたクラスター数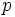 に対して, 最適な分割を求める方法. 最適な分割を求めるのは, 組み合わせ最適化問題の一種であるから, 0-1変数の整数計画問題に定式化すれば, そのアルゴリズムが利用できる.
に対して, 最適な分割を求める方法. 最適な分割を求めるのは, 組み合わせ最適化問題の一種であるから, 0-1変数の整数計画問題に定式化すれば, そのアルゴリズムが利用できる.
2. 階層的分類法
クラスター数が予め定められない場合や分類が段階的にクラスターの併合または細分によって変化することが考えられる場合には, 階層的分類が望まれる.
対象が一つずつ分かれている状態から出発して, 最も近い二つのクラスターを併合することを繰り返して, クラスター数を1ずつ減少させていく方法である. 予め, 二つのクラスター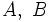 間の距離
間の距離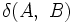 を定めておく必要がある. 手順の概要は, 次のとおりである. ここで, 対象の数を
を定めておく必要がある. 手順の概要は, 次のとおりである. ここで, 対象の数を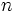 とし, の最終値を
とし, の最終値を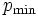 とする.
とする.
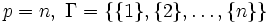 とし,
とし, 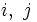
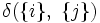 を
を 手順2. に含まれるクラスターの対の中で, 距離が最小であるものを求めて, それらを結合し, の値を1だけ小さくする. 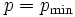 であれば, 終了する.
であれば, 終了する.
手順3. 結合してできたクラスターと他のクラスターの間の距離を計算して手順2にもどる.
クラスター間の距離の定義は, いろいろ考えられているが, 対象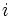 と対象
と対象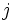 の間の距離
の間の距離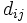 を予め定めておいて, それを用いて表すことが多い. 対象間距離は, 対象のいくつかの特性の測定値から計算される. 特性の単位がすべて揃っているときは, ユークリッド距離が使えるが, 一般には, 重み付きユークリッド距離を用いる. 類似度やアンケートの回答の一致の程度から, 距離を定めることもある. このときは, 類似度などが大きくなるほど, 距離が小さくなるようにする.
を予め定めておいて, それを用いて表すことが多い. 対象間距離は, 対象のいくつかの特性の測定値から計算される. 特性の単位がすべて揃っているときは, ユークリッド距離が使えるが, 一般には, 重み付きユークリッド距離を用いる. 類似度やアンケートの回答の一致の程度から, 距離を定めることもある. このときは, 類似度などが大きくなるほど, 距離が小さくなるようにする.
対象間距離を用いるクラスター間の距離の定義の代表的なものを挙げる.
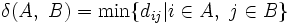
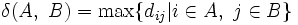
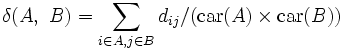
ここで, 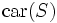 は, 集合
は, 集合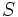 の要素数を表す. 上から順に, 最短距離, 最長距離, 群間平均距離という. 手順1で,
の要素数を表す. 上から順に, 最短距離, 最長距離, 群間平均距離という. 手順1で, 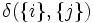 を計算しなければいけないが, 対象間距離を用いるときは,
を計算しなければいけないが, 対象間距離を用いるときは, 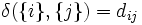 となる.
となる.
凝集型方法では, クラスター間の距離の定義によって, 分類結果が異なる可能性がある. そこで, クラスター間の距離の定義に対応して, 方法に名称が付けられている. 最短距離, 最長距離, 群間平均距離を用いるときは, それぞれ最短距離法, 最長距離法, 群間平均距離法という. 最短距離法の別名としては, 最近隣法, 単連結法などがあり, 最長距離法の別名には, 最遠隣法, 完全連結法などがある. なお, 最短距離法は, 最小木問題のクラスカル法に当たる. 多くのクラスター間の距離を統一的に表わす距離が定義されていて, それを用いる凝集型方法を組み合わせ的方法(combinatorial method)と呼んでいる [6].
凝集型方法は, ある一つのの値に対する分割を求める場合でも, 非常に少ない計算量でよい解を求めるアルゴリズムである. 一般的には, 与えられた目的関数に対して, いつも良い分割を与えるクラスター間の距離の定義は存在しないから, 定義を変えていろいろな分割を求めて, それらの中から最も良いものを選べばよいが, 異なるクラスターに属する2対象間の距離の最小値, すなわち, 最短距離を最大にする場合は, 最短距離法で常に最適解が得られる. 結合していく過程と結合する二つのクラスター間の距離は, 樹形図 (dendrogram) で示される.
凝集型とは逆に, 全対象を一つのクラスターにした状態から出発して, クラスターの分割を繰り返すことにより, トップダウンに階層分類を行う. 逐次二分割方式が多いが, 三つ以上に分割できる方式もある. 時間経過とともに進化して分岐してきたものの分類には適しているが, 凝集型に比べると, はるかに計算量が増える.
[1] 奥野忠一, 久米均, 芳賀敏郎, 吉澤正, 『多変量解析法(改訂版)』, 日科技連出版, 1981.
[2] 大隅昇, L. ルバール他, 『記述的多変量解析法』, 日科技連出版社, 1994.
[3] M. R. Anderberg, Cluster Analysis for Applications, Academic Press, 1973.
[4] T. S. Arthanari and Y. Dodge, Mathematical Programming in Statistics, John-Wiley and Sons, 1981.
[5] B. Everitt, Cluster Analysis, 3rd edn., Edward Arnold, 1993.
[6] G. N. Lance and W. T. Williams, "A General Theory of Classificatory Sorting Strategies 1 - Hierarchical System," Computer Journal, 9 (1967), 373-380.
データ・クラスタリング
(クラスター分析 から転送)
出典: フリー百科事典『ウィキペディア(Wikipedia)』 (2020/07/20 15:24 UTC 版)
クラスタリング (英: clustering)、クラスタ解析(クラスタかいせき)、クラスター分析(クラスターぶんせき)は、データ解析手法(特に多変量解析手法)の一種。教師なしデータ分類手法、つまり与えられたデータを外的基準なしに自動的に分類する手法。また、そのアルゴリズム。
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
- 1 データ・クラスタリングとは
- 2 データ・クラスタリングの概要
- 3 関連項目
「クラスター分析」の例文・使い方・用例・文例
- クラスター分析のページへのリンク

